用 EdgeOne Makers 构建与托管 Agent:从 RAG 检索到智能助手
本文最后更新于 2026年7月8日 晚上
最近折腾了一个小东西:把 oh-my-rime 的配置问答能力,从原来 DocVitePressOMR 里的 RAG / MCP 服务,继续往前推了一步,做成了一个 EdgeOne Makers 托管的 Agent。
生产地址也已经放出来了:
- Agent 页面: https://oh-my-rime.agent.mintimate.cc/
- 文档站接入: https://www.mintimate.cc/
- 知识来源: DocVitePressOMR 文档仓库通过 CNB 知识库向量化后的内容
- 模型来源: 腾讯云 TDP 社区提供的成员专属模型,通过 OpenAI 兼容接口接入
这次最让我感叹的地方,不是“又接了一个大模型接口”,而是 EdgeOne Makers 对 Agent 托管这件事确实省事。官方活动页把它概括成“让 Agent 快速上线,服务全球”,实际用下来也确实是这个体感:会话、环境变量、边缘部署、流式响应、Tracing 都能放在一个很轻的项目里处理。
对于 oh-my-rime 这种面向用户配置问题的项目来说,这种轻量托管刚好合适。它不需要我先搭一整套后端平台,再慢慢把 Agent 相关能力补齐;更像是把已经有的文档知识、配置经验和工具逻辑,直接接到一个可以上线服务的运行环境里。
RAG 检索到 Agent
之前我已经把 薄荷输入法 的文档放进 CNB 知识库,做过一次 VitePress 文档向量化和 RAG 助手:
但是 Rime 配置问题很容易超过“查资料”的范围。
比如用户问:
小狼毫如何设置横向候选栏?
普通 RAG 会检索到相关内容,然后让模型整理答案。可是一个真正可靠的配置助手,还应该继续判断:
- 用户说的是 Windows 小狼毫,不是 macOS 鼠须管。
- 目标文件应该优先是
weasel.custom.yaml,不应该直接让用户改weasel.yaml。 - 配置项要写在
patch:里,并且 slash path 最好加引号。 - 小狼毫上
style/candidate_list_layout: linear是优先方案,必要时再补style/horizontal: true作为兼容后备。
这些不是纯粹的知识检索,而是“检索 + 判断 + 生成配置”的小工作流。于是就有了这次的 oh-my-rime-agent。
sequenceDiagram
actor U as 👤 用户
participant SB as 📦 Sandbox 沙盒
participant KB as 📚 知识库
participant Agent as 🤖 Agent
U->>Agent: 提问 (可上传本地配置文件)
alt 携带配置文件
Agent->>SB: 写入文件并执行诊断脚本
SB-->>Agent: 返回诊断报告 (Tab/语法/patch位置)
end
Agent->>KB: 检索薄荷输入法文档知识
KB-->>Agent: 返回向量检索段落
alt 配置任务
Agent->>Agent: 判断客户端 → 结合沙盒诊断 → 生成 patch
else 非配置任务
Agent->>Agent: 基于文档直接回答
end
Agent-->>U: 流式返回答案 (Thinking + Tool Chain + Content)
Tool Calling
如果只把文档检索结果丢给模型,回答仍然可能“不够稳”。Rime 的配置细节太多了:
- Windows 小狼毫和 macOS 鼠须管的目标文件不同。
- UI 样式、schema 行为、候选词数量、快捷键,各自对应的文件层级不同。
*.custom.yaml的patch:写法有坑,不小心就会覆盖父级配置。- 部分配置项有平台兼容差异。
所以我给 Agent 定义了一组 Rime 专用工具(Tool Calling):
| 工具 | 作用 |
|---|---|
search_docs |
检索 oh-my-rime / DocVitePressOMR 知识库 |
resolve_client |
把“小狼毫、鼠须管、Fcitx5、IBus、同文”等说法解析成客户端 |
target_file |
根据平台和任务判断最安全的 *.custom.yaml |
make_patch |
根据配置路径生成安全的 YAML patch |
check_yaml |
对用户给出的 Rime YAML / *.custom.yaml 片段做结构化静态检查 |
diagnose_rime_directory |
新增:在沙盒中对用户上传的多个 Rime 配置文件进行批量和关联性体检 |
recipe |
返回高频配置配方,比如横向候选栏、候选词数量、切换配色 |
sequenceDiagram
actor U as 👤 用户
participant Agent as 🤖 Agent
participant Tools as 🧰 Rime 工具/沙盒
U->>Agent: 提出配置 / 排错问题
opt 上传了配置文件
Agent->>Tools: diagnose_rime_directory 在沙盒中集中体检
end
Agent->>Tools: search_docs 获取上下文
alt 高频配置
Agent->>Tools: recipe 直接取配方
else 配置不生效 / 贴了 YAML
Agent->>Tools: check_yaml 做结构化检查
else 复杂配置
Agent->>Tools: resolve_client → target_file → make_patch
end
Tools-->>Agent: 返回诊断报告、目标文件或 patch 结果
Agent-->>U: 整理成最终的可执行配置建议
以“小狼毫横向候选栏”为例,recipe 可以直接返回:
1 | |
同时附带目标文件:
1 | |
这就比模型临场发挥要可靠得多。Agent 最终回答也更像一个配置助手,而不是泛泛地解释 Rime 原理。
EdgeOne Makers 托管
EdgeOne Makers 这次给我的体感是:它很适合托管这种“不大,但需要边缘响应和 Agent 状态”的项目。
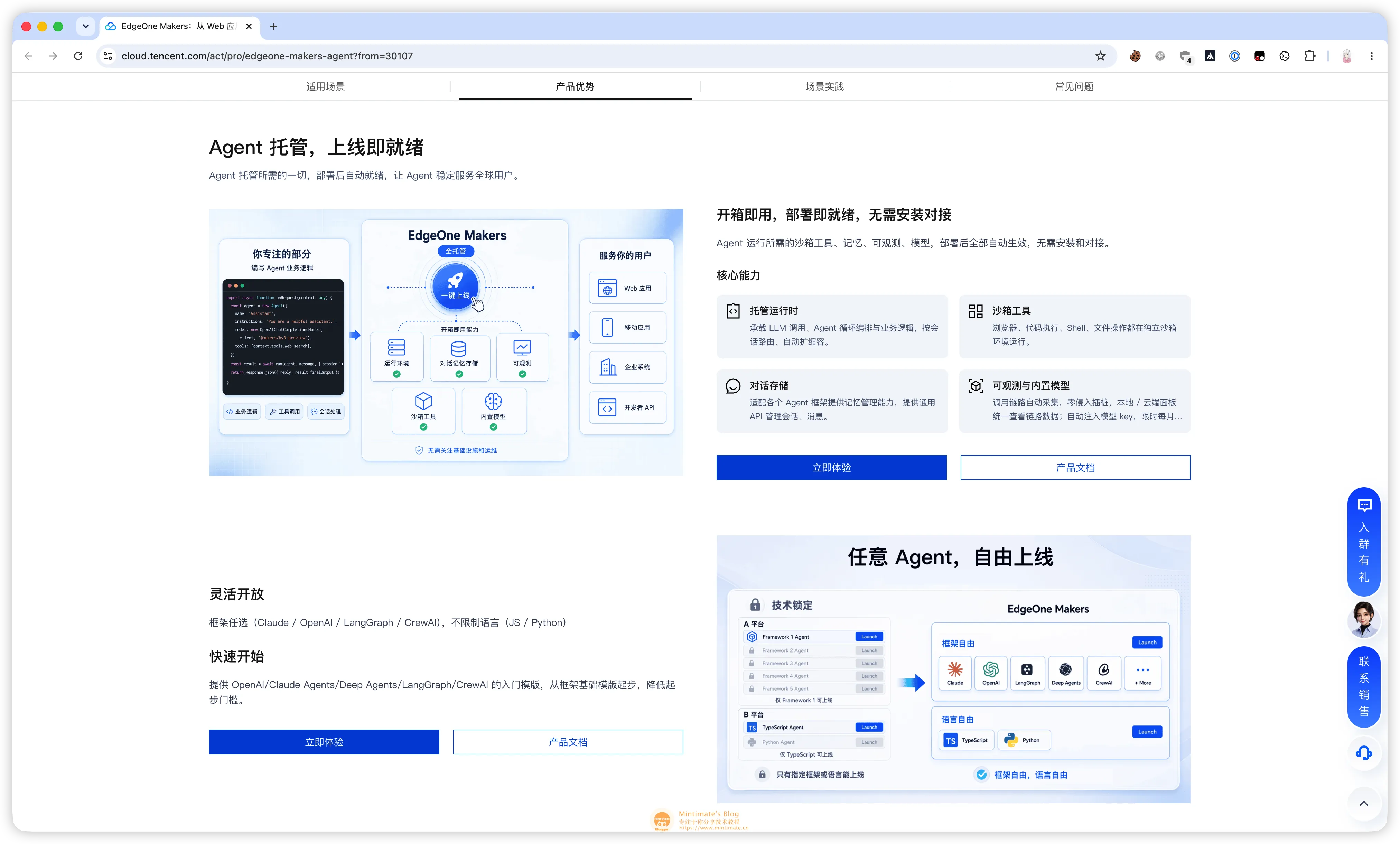
官方活动页里有一句描述我很有共鸣:Agent 部署后自动获得运行时、沙箱、记忆、可观测和内置模型等能力。换成这次 oh-my-rime-agent 的语境,就是我不用把这些能力拆成很多基础设施自己拼:
- 运行时负责承载
/chat和/stop。 - 会话 ID 通过
makers-conversation-id传递和管理。 - 环境变量直接放 CNB 知识库、模型网关和工具开关。
- SSE 可以直接把
thinking、tool_call、ai_response往前端吐。 - Sandbox 可以做配置片段检测、临时文件处理和后续更复杂的可执行校验。
- Tracing 可以把知识库、工具调用和 LLM Turn 串起来。
为了更直观地说明,下表对比了传统服务器部署与 EdgeOne Makers 托管 Agent 的核心差异:
| 对比维度 | 传统服务器部署 | EdgeOne Makers 托管 |
|---|---|---|
| 部署与运维 | 需要自行配置服务器、Nginx、SSL 证书、Docker 容器等,配置繁琐 | CLI 一键部署,可自动管理域名证书,并享用全球边缘节点加速 |
| 会话与记忆 | 需自建或引入 Redis、数据库等服务来存储和维护多轮对话状态 | 内置 makers-conversation-id 与 context.store 自动支持状态管理 |
| 安全沙箱 | 需要自行构建并维护隔离的代码运行环境,防范恶意执行风险 | 原生注入 context.sandbox 容器,零配置即可使用安全的隔离沙箱 |
| 链路追踪 | 需要额外部署并对接 OpenTelemetry、Jaeger 等复杂的追踪链路 | 内置 context.tracer 服务,自动将 LLM、工具和知识库调用串联 |
| 边缘与流式 | 需调优 Nginx 缓存以支持流式 SSE,难以保证全球用户的低延迟响应 | 原生对 SSE 友好,在全球边缘节点就近执行和分发,响应快 |
所以我们快速构建了:
oh-my-rime-agent 项目结构非常轻:
1 | |
暴露的接口也很克制:
POST /chat: 对话接口,使用 SSE 返回事件。POST /stop: 停止当前会话。
部署时用 CLI 就能完成:
1 | |
环境变量可以直接在后台进行设置:
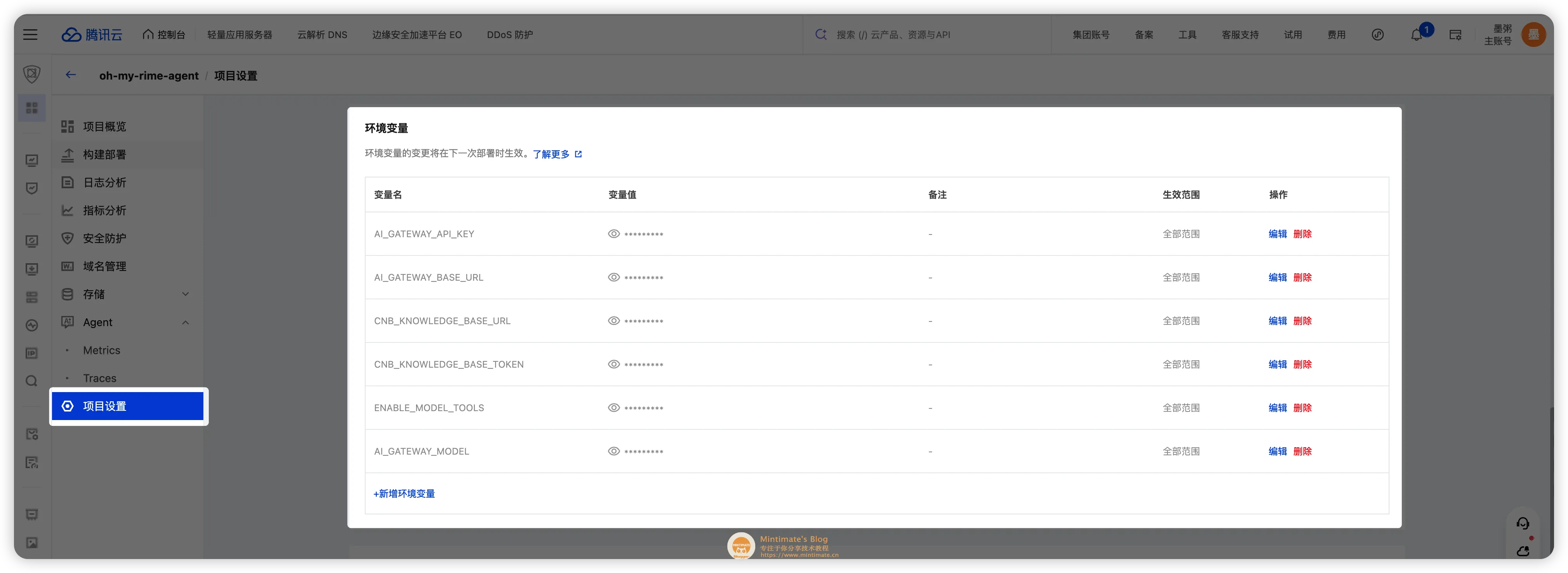
也可以直接通过 CLI 设置:
1 | |
部署完以后,用 curl 就能验证:
1 | |
整体感觉是:不用自己额外搭一层服务,也不用为了一个小 Agent 单独维护一套后端运行环境。对于个人项目和文档项目,这个体验确实很香。
沙盒能力
这里还有一个值得单独说的点:EdgeOne Makers 的 Agent 运行时会注入 context.sandbox。它不是让业务代码自己拼一个远端执行服务,也不是让模型凭空“想象”执行结果,而是在 Agent 上下文里直接拿到一个隔离的执行环境。
这个EdgeOne Makers 沙盒能力可以做几类事情:
- 执行短代码片段,比如用 Python / JavaScript 检查用户上传内容。
- 读写临时文件,适合处理用户贴来的配置、词库或导出的日志。
- 配合浏览器或命令执行能力,做一些比纯文本推理更接近真实环境的验证。
- 把“模型建议”升级成“工具检查后的建议”,降低凭经验回答带来的误判。
对于 oh-my-rime-agent 来说,最直接的价值就是把“配置建议”进一步升级成“配置检测”。Rime 的问题经常不是用户不知道配置项,而是配置文件写法有一点点不符合规则:比如 patch: 没有放在第一条非注释内容、把 custom 文件写成普通嵌套 YAML、或者缩进里混入了 Tab。这些问题如果是单纯让大模型去猜,很容易出现误判。
现在的 oh-my-rime-agent 不仅仅是依赖单纯的静态规则校验,当接收到用户上传的配置文件时,它会利用 context.sandbox 启动一个真实的隔离执行环境:将文件写入沙盒临时目录,并通过 Python 脚本进行批量扫描,不仅能统计文件信息,还能跨文件排查依赖和语法规则。
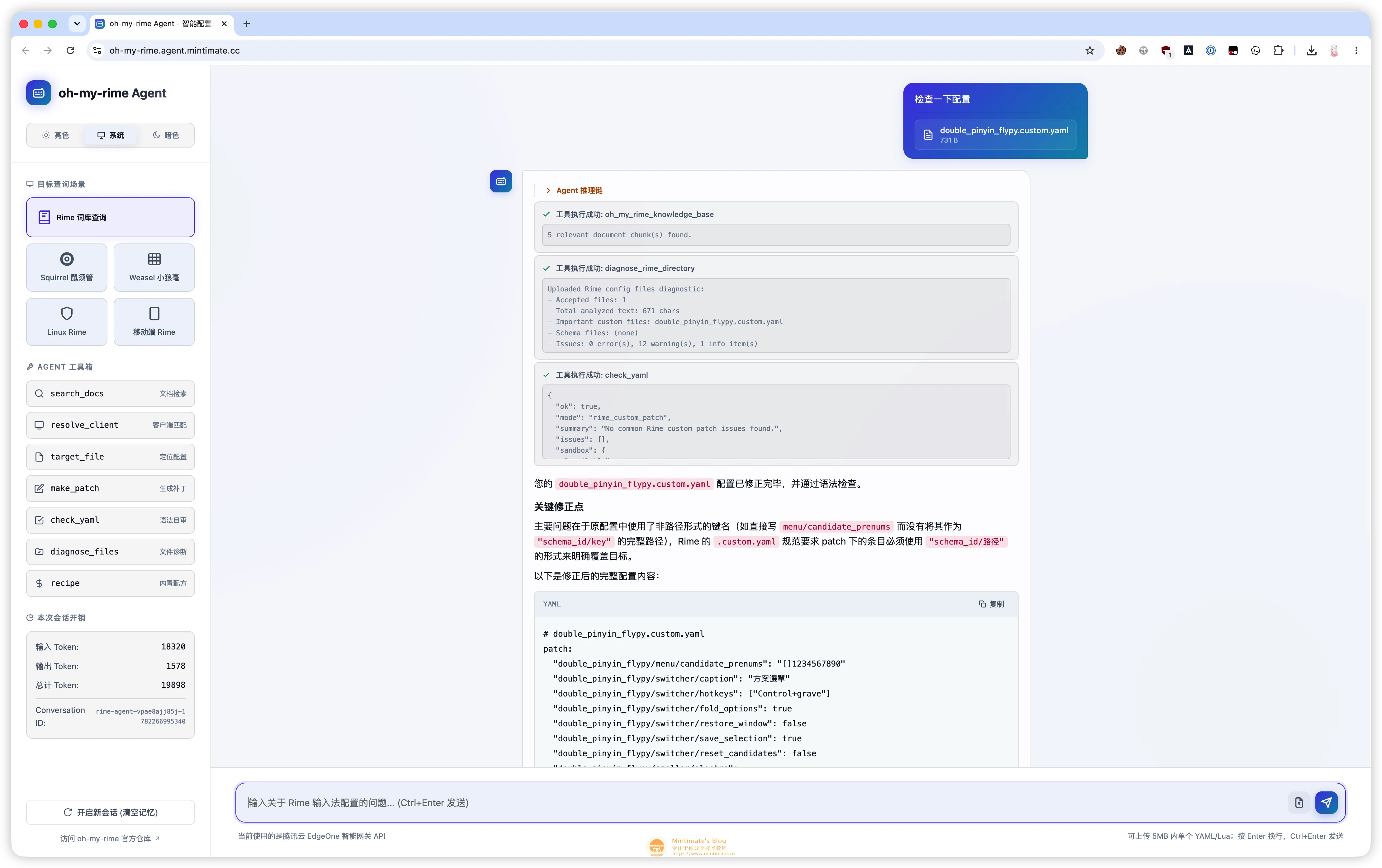
具体的 sandbox.runCode(...) 代码形态如下:
1 | |
现在,前端(Web 端)支持用户直接上传配置文件或整个配置目录。在请求时,这些文件内容会打包进 configFiles 传给后端。Agent 在接收到带有文件的请求时,会在真正求助大模型前,先通过 context.sandbox 启动一个沙盒级别的诊断:
- 写入沙盒:Agent 自动把所有上传的配置文件写入沙盒的临时隔离目录。
- 执行诊断:在沙盒中运行探测脚本,对这批文件进行集中体检,比如检查 YAML 语法、识别 custom 补丁的首行
patch:规则、扫描是否混入 Tab 缩进等。 - 注入上下文:将沙盒返回的结构化诊断报告(例如哪几个文件有报错,具体在第几行)作为额外上下文(Extra Context)直接喂给大模型。
此时,SSE 事件流里就会多出极其关键的一环:
1 | |
这样一来,模型就不再是凭空猜测用户的配置为什么不生效,而是拿着沙盒跑出来的“体检报告”,结合它本身具备的 Rime 知识,准确地向用户解释问题,并给出 make_patch 后的正确配置。这种 前端上传文件 -> 沙盒运行校验 -> 模型深度解释 的闭环,才是托管 Agent 真正有别于普通 RAG 机器人的核心价值所在。
Agent 优化尝试
工具调用轮次优化
一开始如果完全让模型自由调用工具,流程可能是这样的:
- 调用
resolve_client,确认用户说的是小狼毫。 - 调用
target_file,确认目标文件是weasel.custom.yaml。 - 调用
make_patch,生成 YAML patch。 - 再整理最终回答。
这当然能跑,但在边缘环境里,每多一轮 LLM Turn 都意味着额外延迟和 Token 成本。用户只是问一个高频配置问题,没必要绕这么远。
所以后来我在系统提示词里加了更明确的工具策略:
- 如果命中高频任务,比如横向候选栏、候选词数量、切换配色,直接调用
recipe。 - 如果用户已经明确平台,不再调用
resolve_client。 - 只有非标准配置,才走
target_file+make_patch。 - 用户询问配置是否合法、配置不生效、或者贴出了 YAML / custom 片段时,优先调用
check_yaml。 - 只有生成了复杂 patch,才额外调用
check_yaml自审。
这类策略很朴素,但很有效。Agent 从“每一步都问模型”变成“常见问题走快捷配方,复杂问题再拆步骤”。实际体验里,横向候选栏这种问题一轮工具调用就能解决,响应也轻快很多。
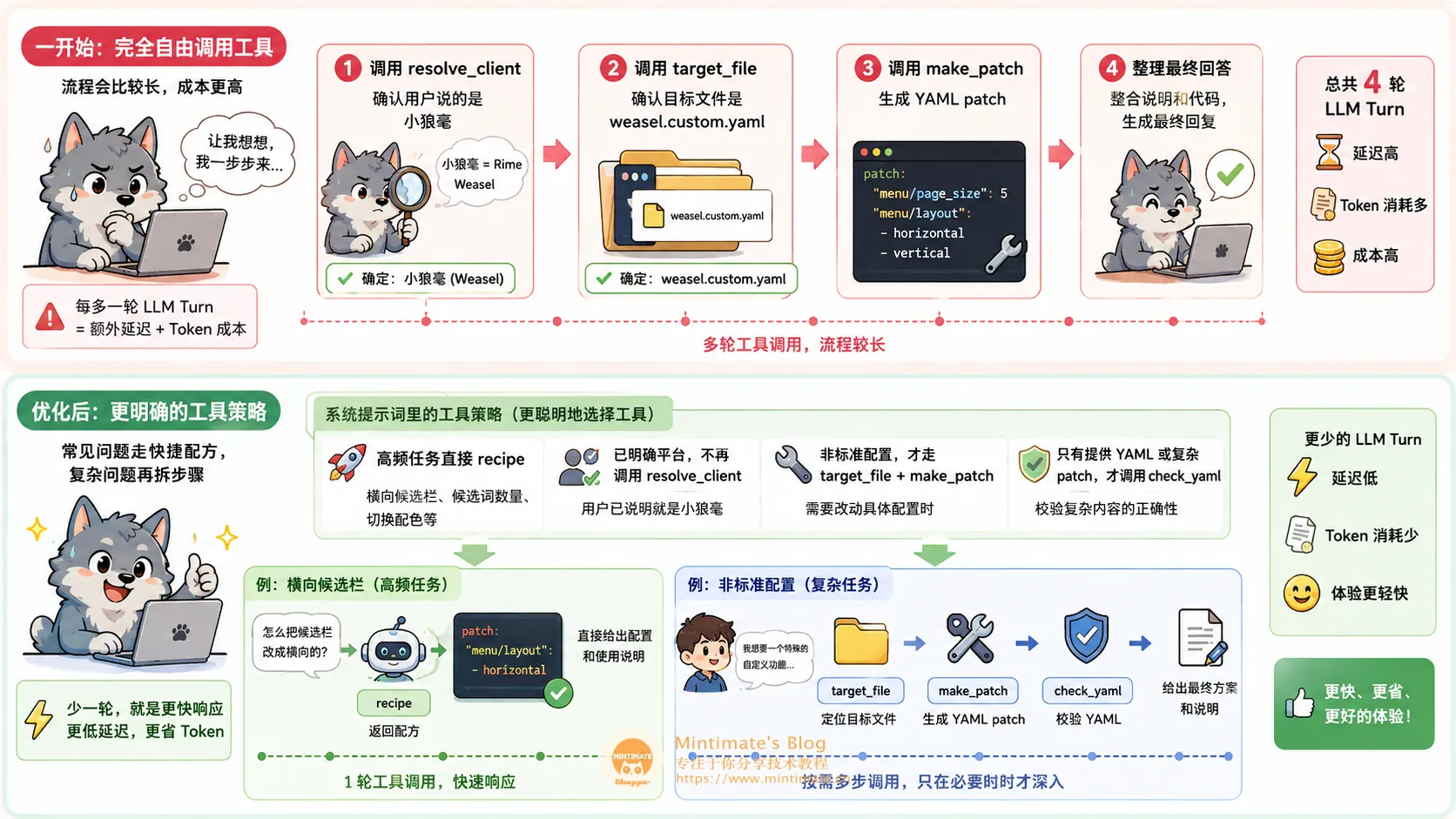
下图是一次真实 /chat SSE 调用整理出来的工具链过程:先检索知识库,再命中 recipe,最后返回 weasel.custom.yaml 和对应 patch。
sequenceDiagram
actor U as 👤 用户
participant Agent as 🤖 Agent
U->>Agent: 配置问题
alt 命中高频配置
Agent->>Agent: recipe 直接返回
else 非高频配置
Agent->>Agent: 客户端 → 目标文件 → 生成 patch
end
Agent-->>U: 最终回答
模型与 Tool Calling 的坑
这次模型侧用的是自部署 vLLM,通过 OpenAI 兼容接口接入。大体启动方式类似:
1 | |
我最初也想完整使用 streaming tool call delta,把工具调用和最终文本都流出来。但实际测试时,vLLM 的 streaming tool call delta 兼容性不太稳定,工具函数名可能在多个 chunk 里重复出现,最后拼出类似:
1 | |
这就没法正常执行工具了。
最后采用了一个工程上更稳的折中方案:
- 工具规划阶段使用非流式 Chat Completions。
- 模型返回工具调用后,Agent 执行工具,并把
tool_call、tool_result发给前端。 - 工具结果补齐后,再发起最终回答请求。
- 最终回答阶段使用 streaming,把
ai_response增量输出。
这样用户仍然能看到过程:
1 | |
它不是最炫的实现,但它稳定、可控,也符合这个项目的复杂度。
EO Makers Tracing
Agent 一旦有了 RAG、工具调用、流式输出,排查问题就不能只看最终回答了。到底是知识库没查到?工具没选对?模型最后整理歪了?这些都需要链路记录。
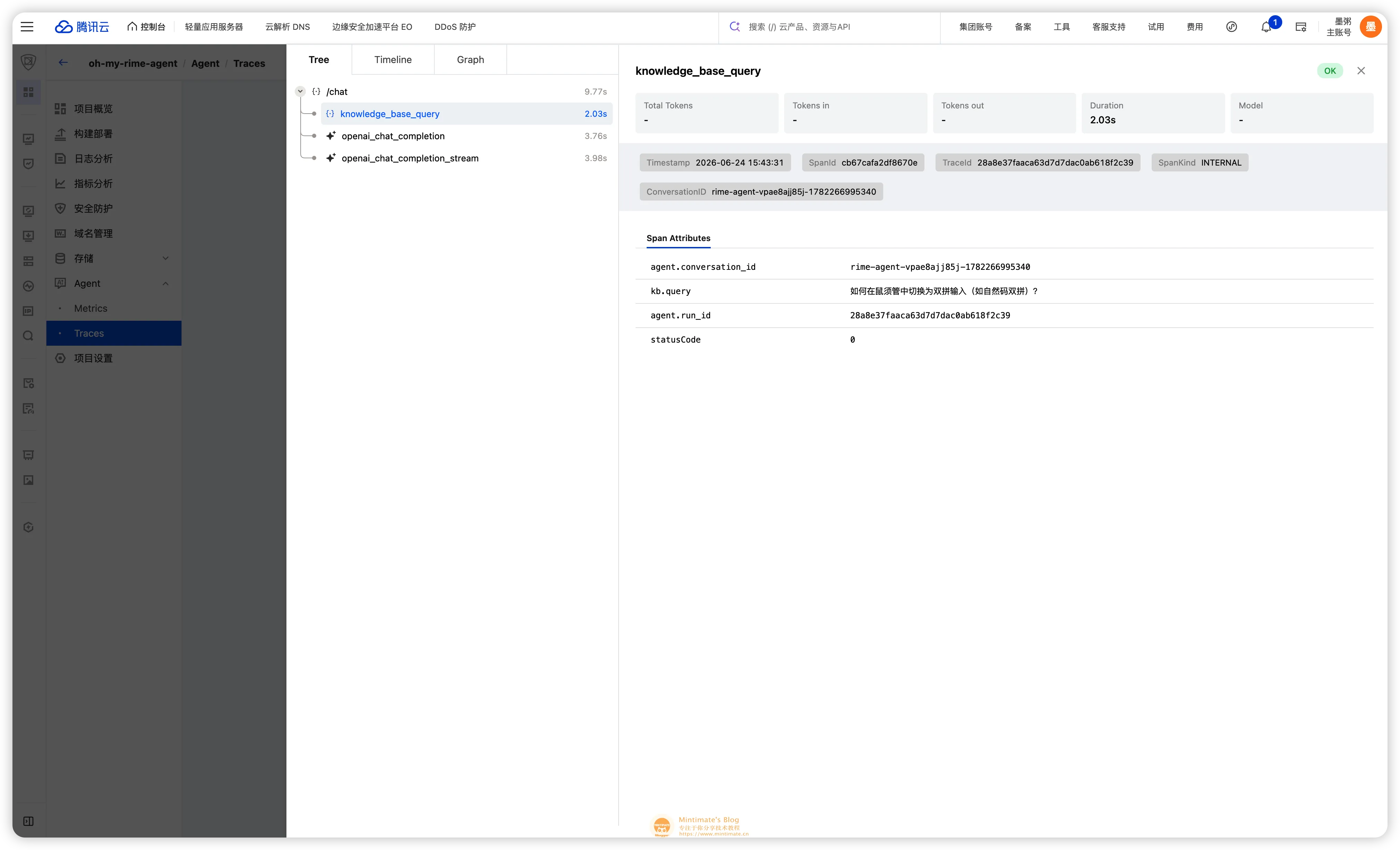
EdgeOne Makers 这里有一个很舒服的能力:执行上下文里会有 context.tracer。我可以直接给当前会话打属性:
1 | |
对于平台没法自动感知的部分,比如 CNB 知识库请求和本地工具执行,也可以手动包一层 span:
1 | |
工具调用也是类似:
1 | |
LLM 调用部分则尽量按 OpenInference / OpenTelemetry 习惯补属性:
1 | |
最后把 Token 用量也写进去:
1 | |
这样一来,一次对话不再是黑盒,而是能看到:
- 知识库查询用了多久。
- 模型在哪一轮选择了什么工具。
- 工具返回了什么摘要。
- 最终回答用了多少 Token。
接入 VitePress
还有一个接入重点,让现有的 VitePress 文档站配合 oh-my-rime Agent,更丝滑地实现站内 AI 问答,当然有能力的用户也可以直接访问 Agent 页面,接入本地的 AI 客户端工具。
也就是说,用户仍然在 薄荷输入法文档站 里阅读教程、查配置、看示例;当他遇到具体问题时,可以直接打开右上角的 Assistant 提问。VitePress 负责承载文档和交互入口,EdgeOne Makers 上托管的 oh-my-rime Agent 负责理解问题、检索知识库、判断 Rime 客户端和生成配置建议。
这次新增的 Agent 接入,更像是给 VitePress 文档站补上一层“会做配置判断”的问答能力。前端只需要在主题里挂一个 Assistant 入口,把用户问题发送给 oh-my-rime.agent.mintimate.cc/chat,再把 Agent 返回的内容展示出来。
Agent 返回的是 SSE 事件流,VitePress 侧可以按需要选择两种消费方式:
- 非流式接口:只收集
ai_response,最后返回一个完整回答。 - 流式接口:原样透传 SSE,让前端看到
thinking、tool_call、tool_result、usage等事件。
这样一来,VitePress 不需要承担复杂 Agent 编排,只负责把“文档站里的问题”送出去、把“Agent 的回答和过程”展示回来;oh-my-rime-agent 则专注做配置推理和工具调度。这个边界比较舒服,也很适合文档站逐步增强 AI 问答能力。
实际效果就是:用户停留在 www.mintimate.cc,右上角多了一个 Assistant 入口。打开后可以直接在当前文档语境里提配置问题,后端再把请求交给 oh-my-rime Agent。
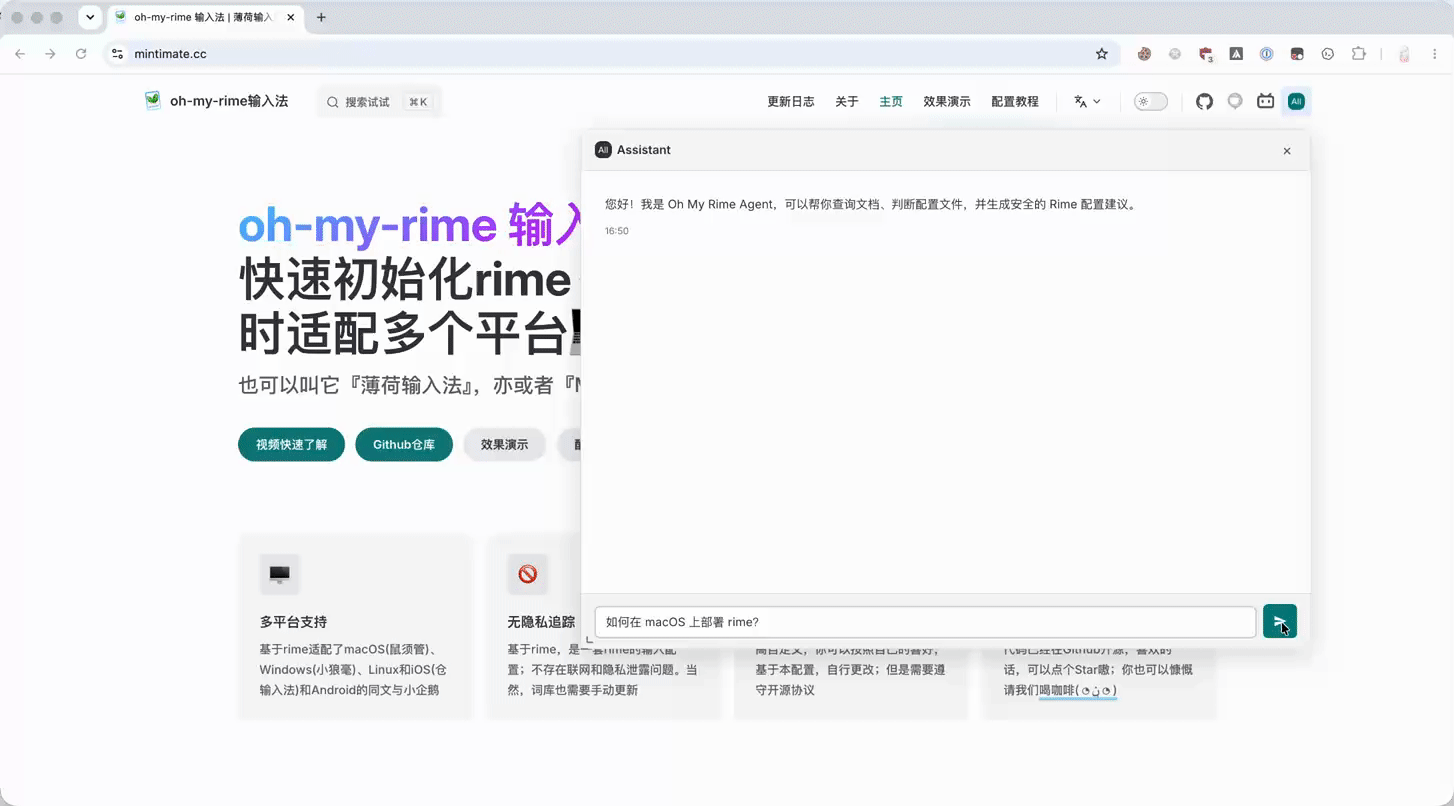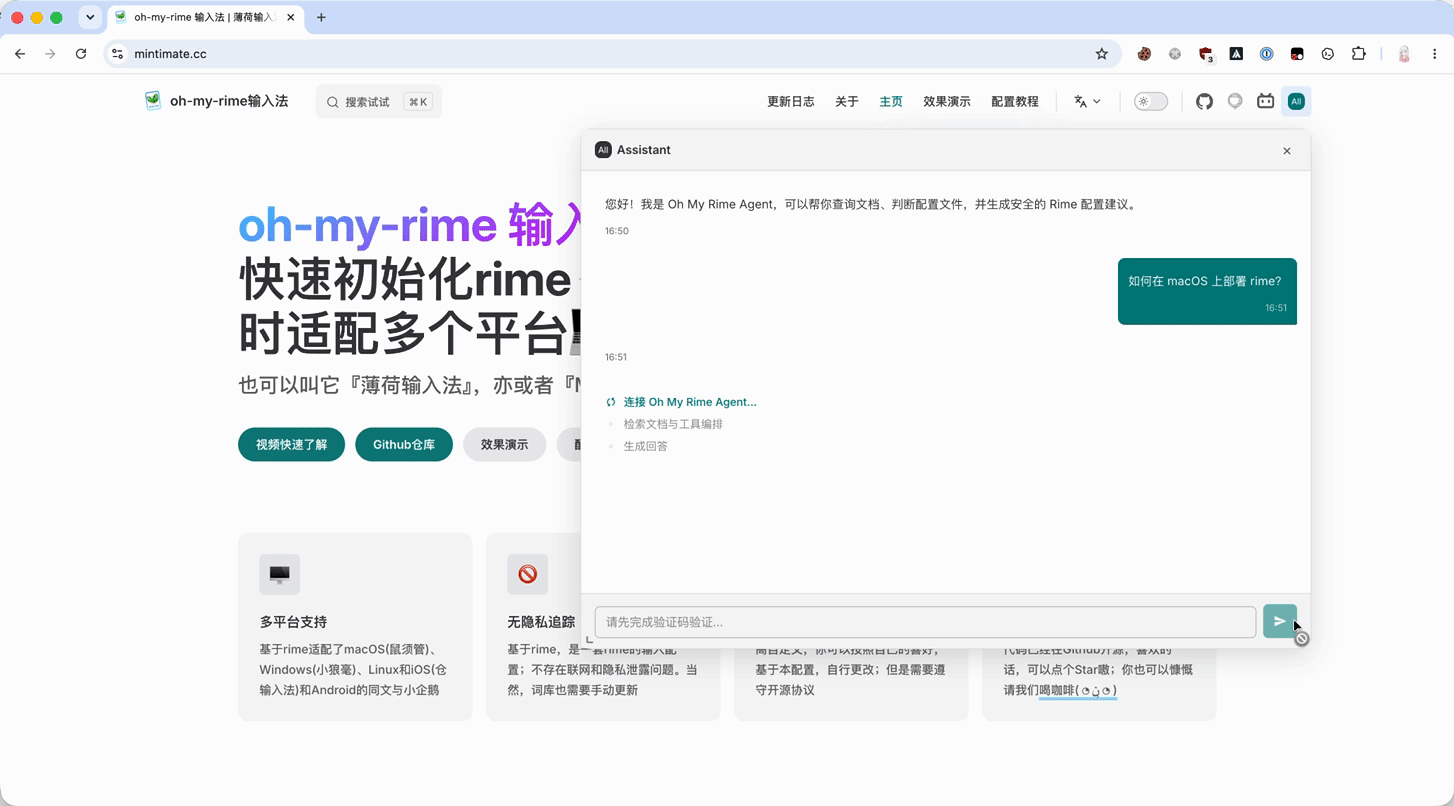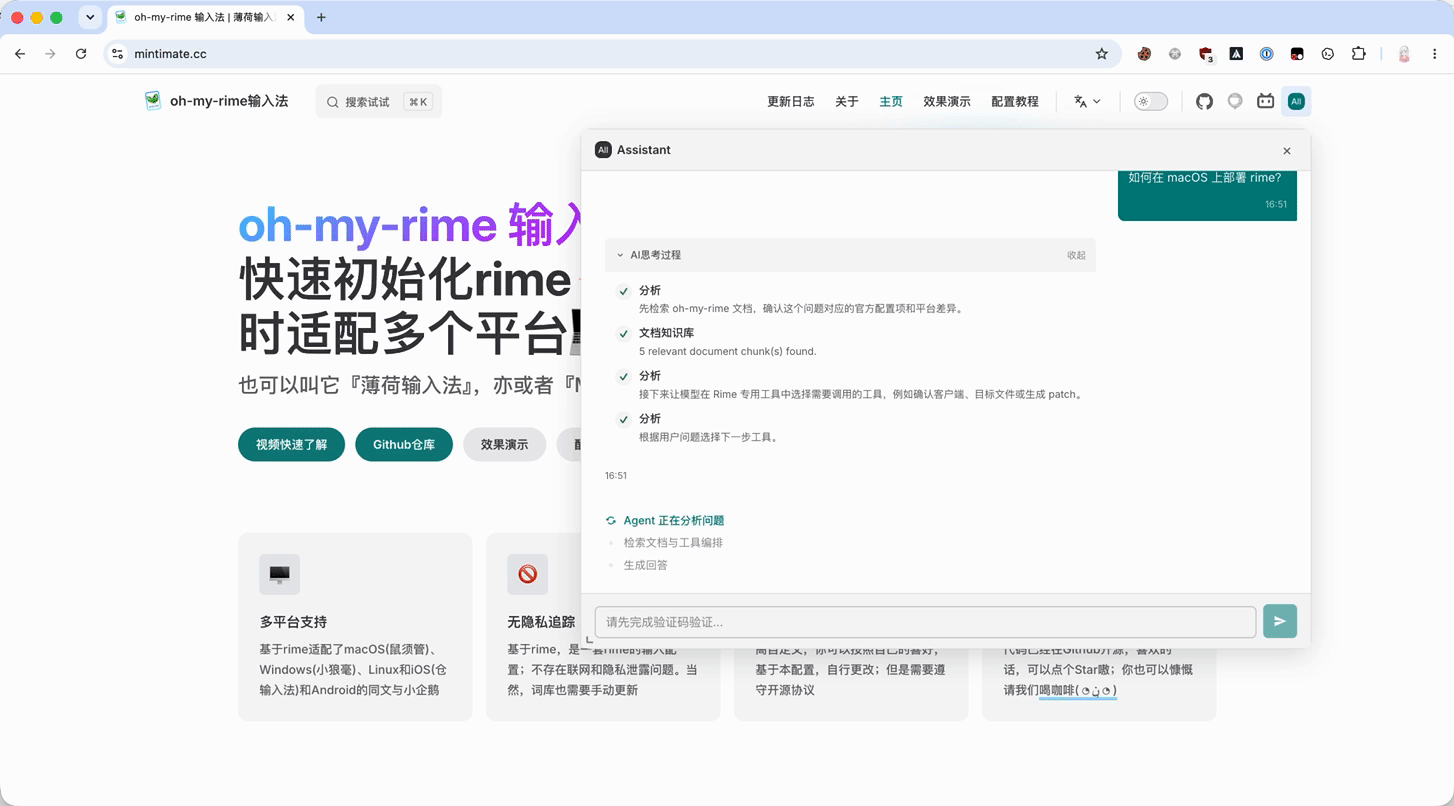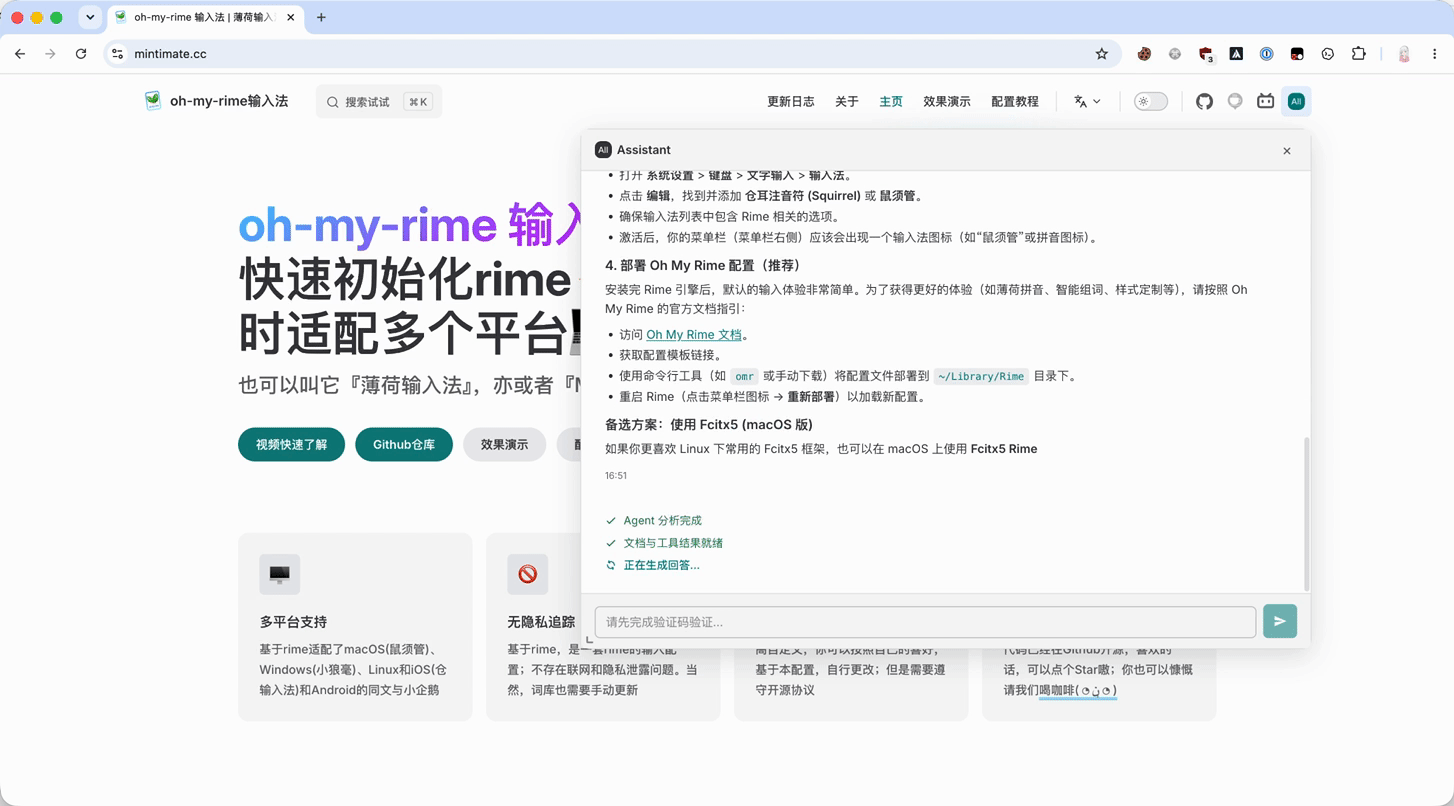
具体详细步骤,可以参考源码 PR:
应用后的效果
部署完成后,Agent 页面本身已经可以作为一个轻量的调试入口。左侧可以看到目标客户端系统、工具箱、Token 统计和会话 ID;中间则是面向用户的 Rime 配置助理入口。
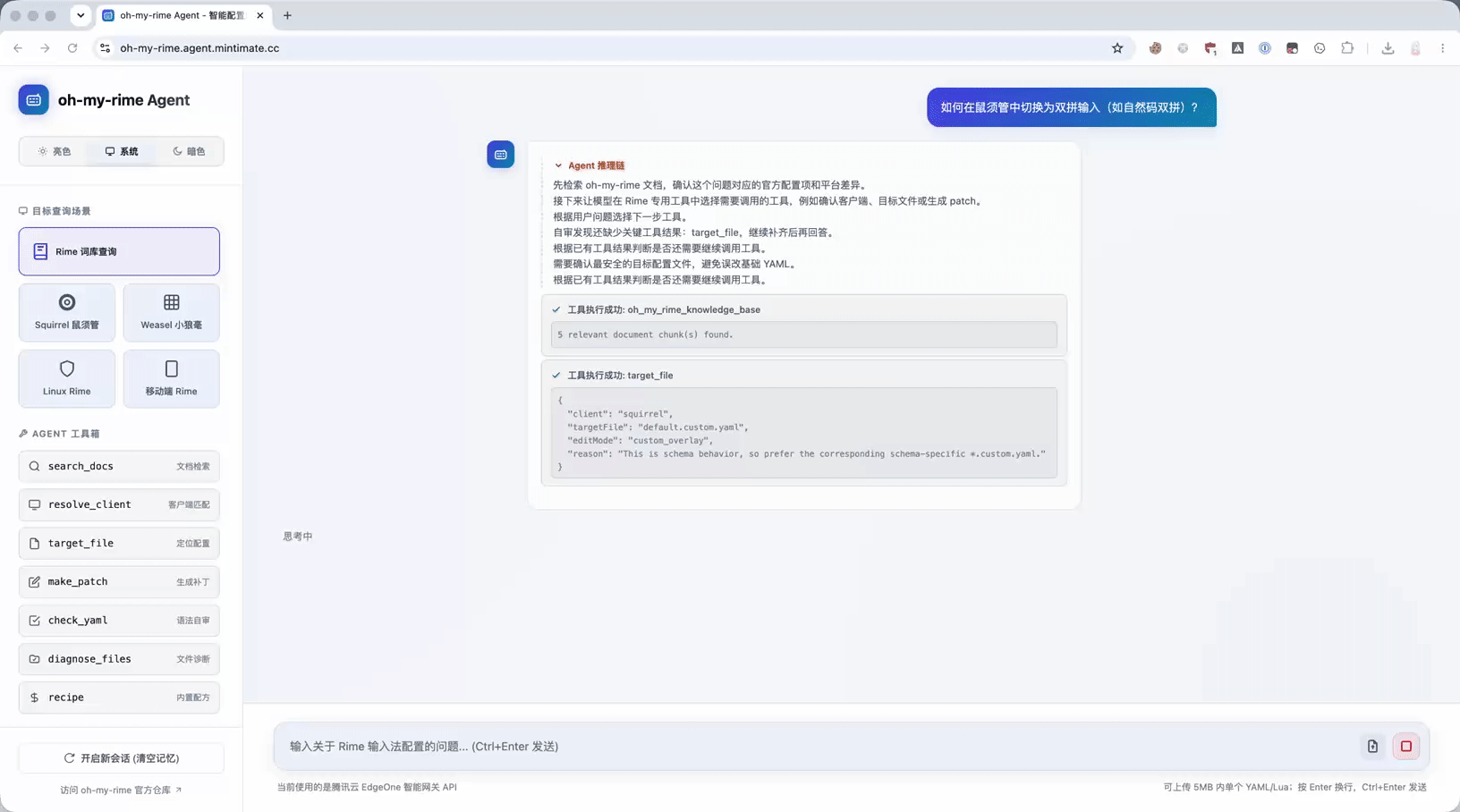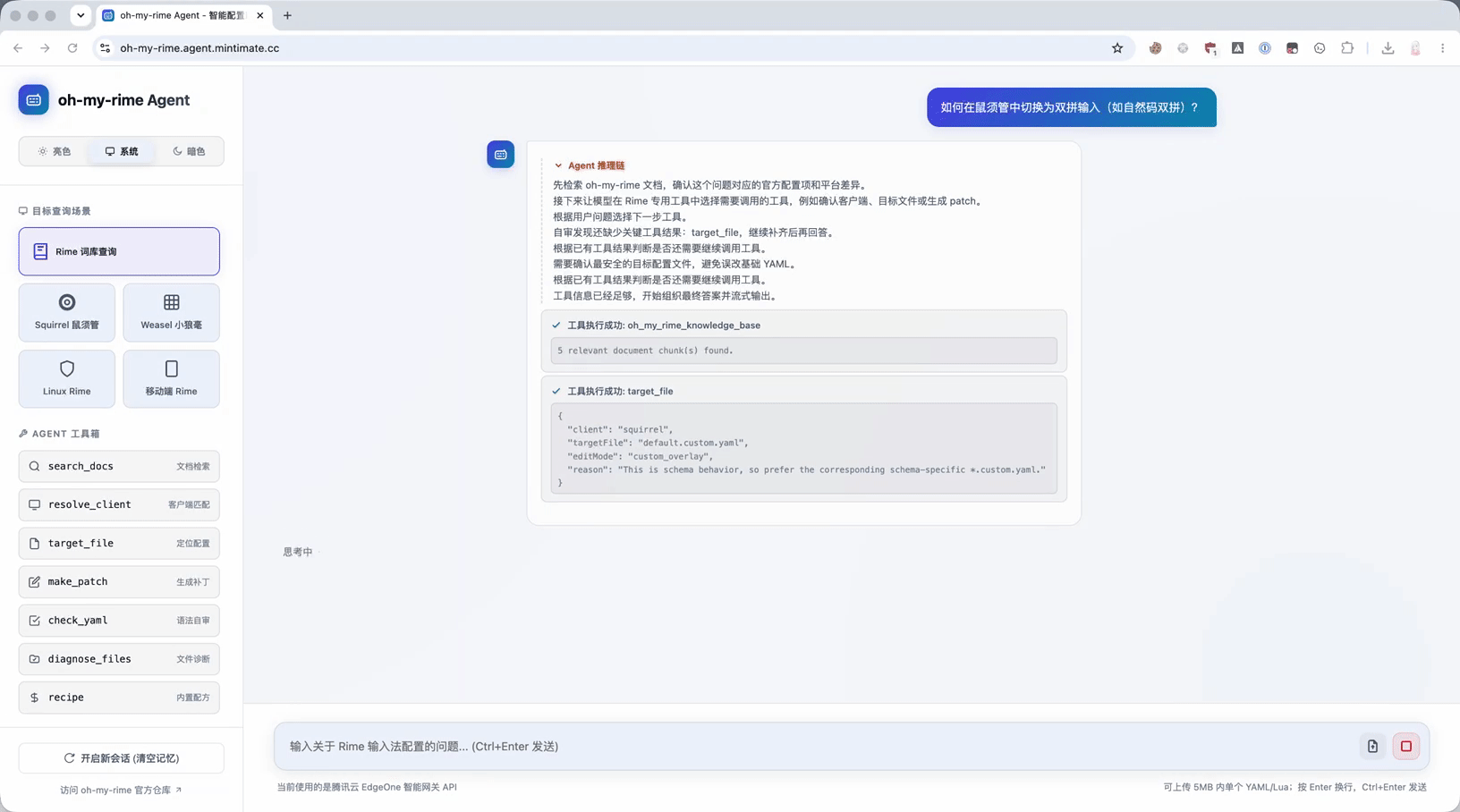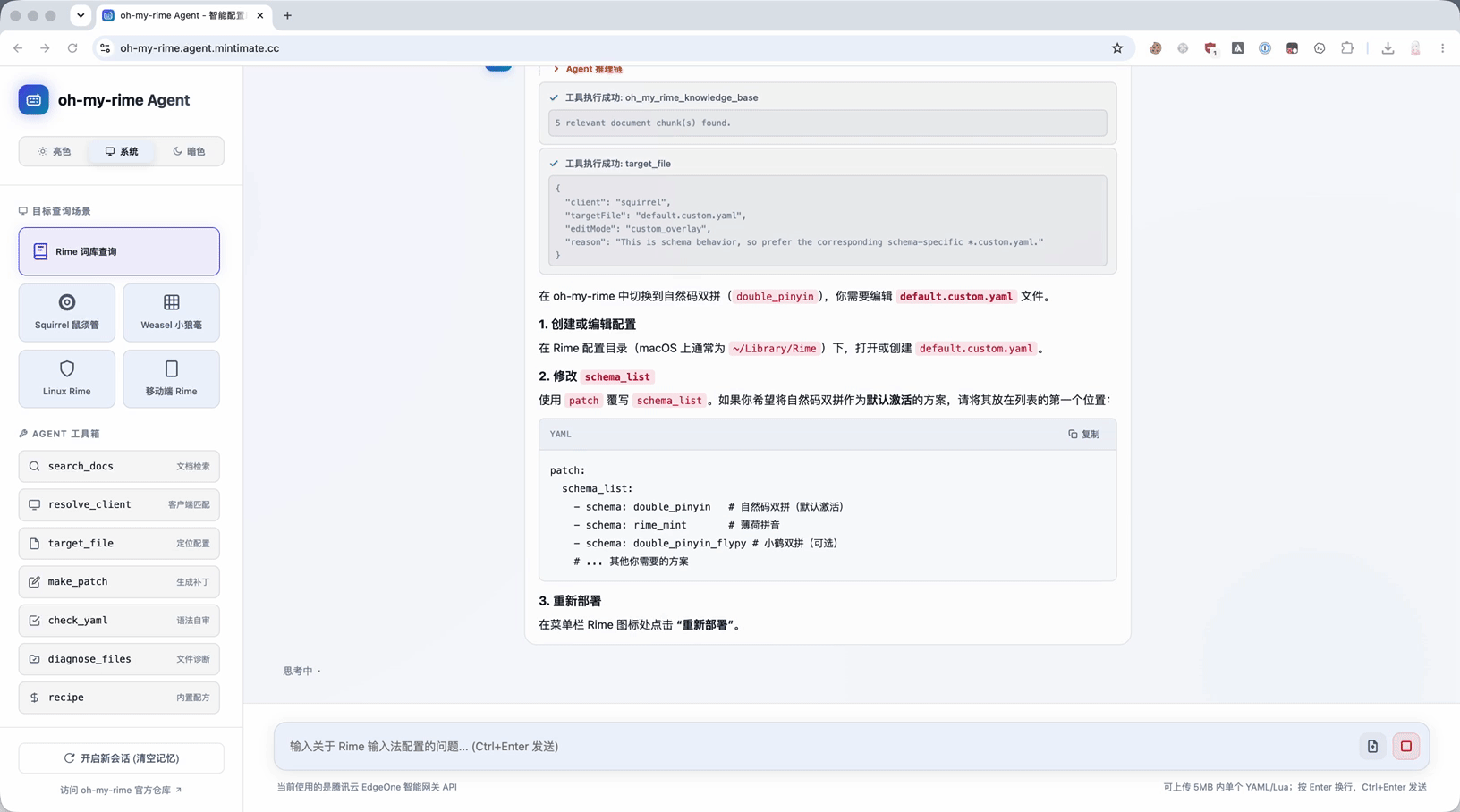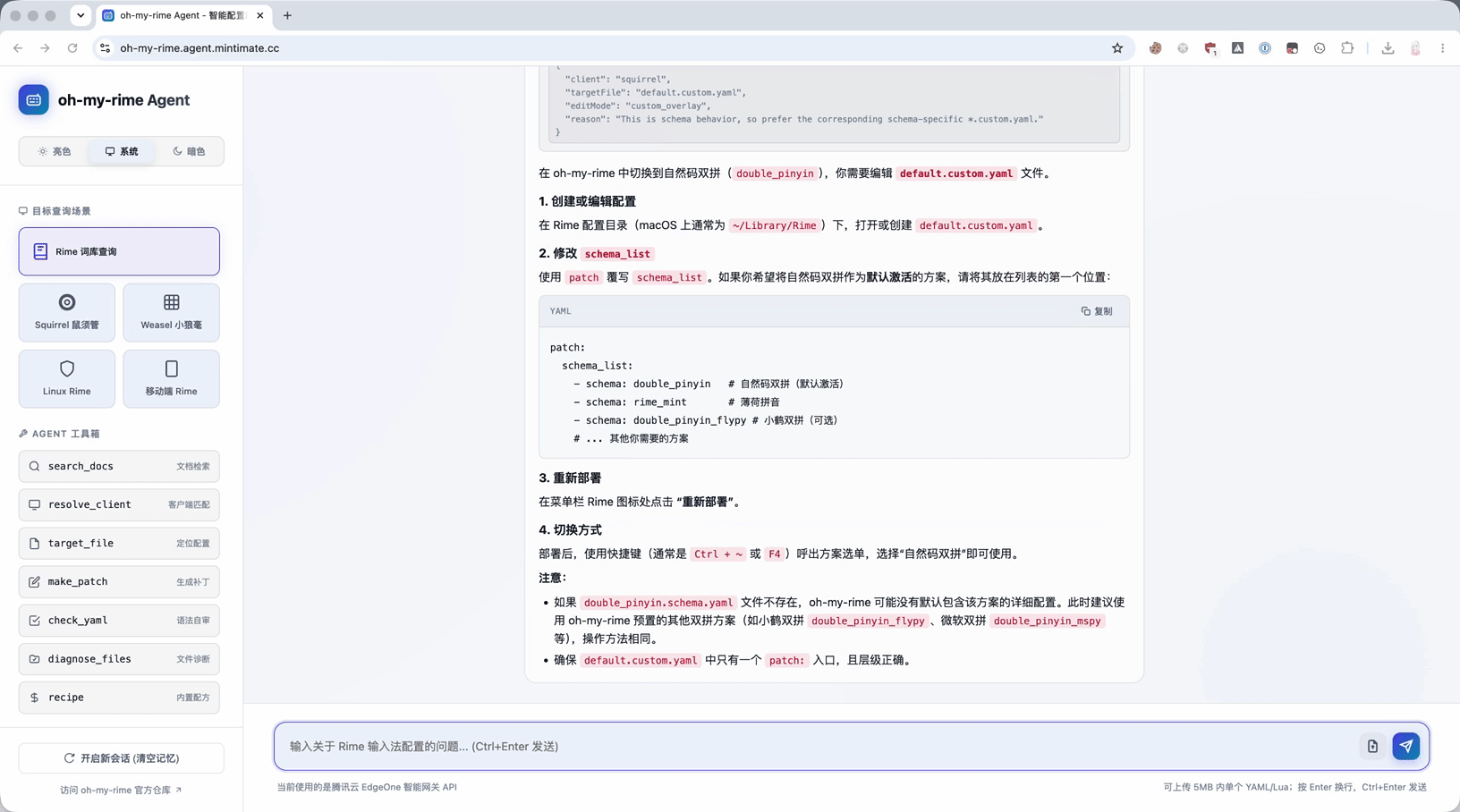
以“如何在鼠须管中切换为双拼输入(如自然码双拼)?”为例,现在 Agent 的理想路径是:
- 先检索 DocVitePressOMR / oh-my-rime 文档,确认上下文。
- 识别到这是鼠须管的高频配置。
- 直接调用
recipe。 - 返回目标文件启用自然码双拼方案。
- 给出 YAML patch,并提醒重新部署或重新加载配置。
最终回答会更贴近用户真正需要的东西:
1 | |
同时还能补上说明总结:
- 配置文件:
default.custom.yaml - 关键配置:在
schema_list中添加 -schema: double_pinyin - 操作:部署后通过方案选择器切换。
这就是 Agent 相比普通 RAG 更有价值的地方:它不仅知道文档在哪里,还知道这类问题应该落到哪个文件、怎么写配置、有哪些坑要避开。
后续计划:鉴权
目前这个 Agent 已经能跑,但公开服务还有一个必须补上的点:鉴权。
短期我准备先做几层轻量保护:
- 限制公开页面的请求频率,避免被刷。
- 为
/chat增加简单的访问凭据或签名校验。 - 对
makers-conversation-id做更严格的会话约束。 - 在 DocVitePressOMR 转发层保留可扩展的鉴权入口。
中期会考虑更完整的方案:
- 匿名用户只允许普通文档问答和有限次数的配置生成。
- 管理员或维护者可以使用更高额度、更长上下文的 Agent。
- 对外开放接口时增加时间戳签名,避免被第三方直接盗用。
- 如果后面接入用户系统,再把会话、额度和审计日志关联起来。
这部分不会一开始就做得很重。oh-my-rime Agent 的定位还是文档项目里的配置助手,不是商业 SaaS。但只要服务公开,就不能完全裸奔,这个坑得提前填。
END
这次做完最大的感受是:EdgeOne Makers 托管 Agent 的心智负担确实很低。
DocVitePressOMR 原本已经有文档、RAG、MCP 和云函数;oh-my-rime-agent 则把这些资料进一步组织成能判断配置文件、生成 patch、展示执行状态的助手。整个过程不用把项目改得很重,也不用额外维护复杂后端,边缘侧直接承接对话和工具调用,挺适合个人项目慢慢把 AI 能力接进去。
Agent 当然不是“套个模型接口”就结束。真正有意思的部分,还是那些工程取舍:哪些问题走 RAG,哪些步骤工具化,哪些高频场景做 recipe,哪里必须流式,哪里要为了稳定放弃流式,最后又如何用 Tracing 把整条链路看清楚。
后面把鉴权补上,这个 oh-my-rime 配置助手就更像一个可以长期挂在文档站里的小工具了。
