macOS 部署 Ollama 和 Open WebUI,实现本地运行 DeepSeek 大模型
本文最后更新于 2026年4月2日 上午
2025年1月20日,杭州的一家公司开源推理模型 DeepSeek-R1,一经推出就震撼了世界。
不单单是媲美 OpenAI O3 的推理能力,更是用极低的成本,惊艳了世界。更何况,DeepSeek-R1 是开源的,任何人都可以部署,实现本地运行大模型,真正的 OPEN。
本来各个 AI 厂商还在牌桌上打牌,突然就有人把牌桌掀翻了。
比较有趣的是,DeepSeek 671B 模型,有非常多的“蒸馏版本”,而且“蒸馏版本”对高端显卡的依赖低,性能也基本满足个人使用。
本文将介绍如何在 macOS 上部署 Ollama 和 Open WebUI,实现本地运行 DeepSeek 大模型。
最后的效果:
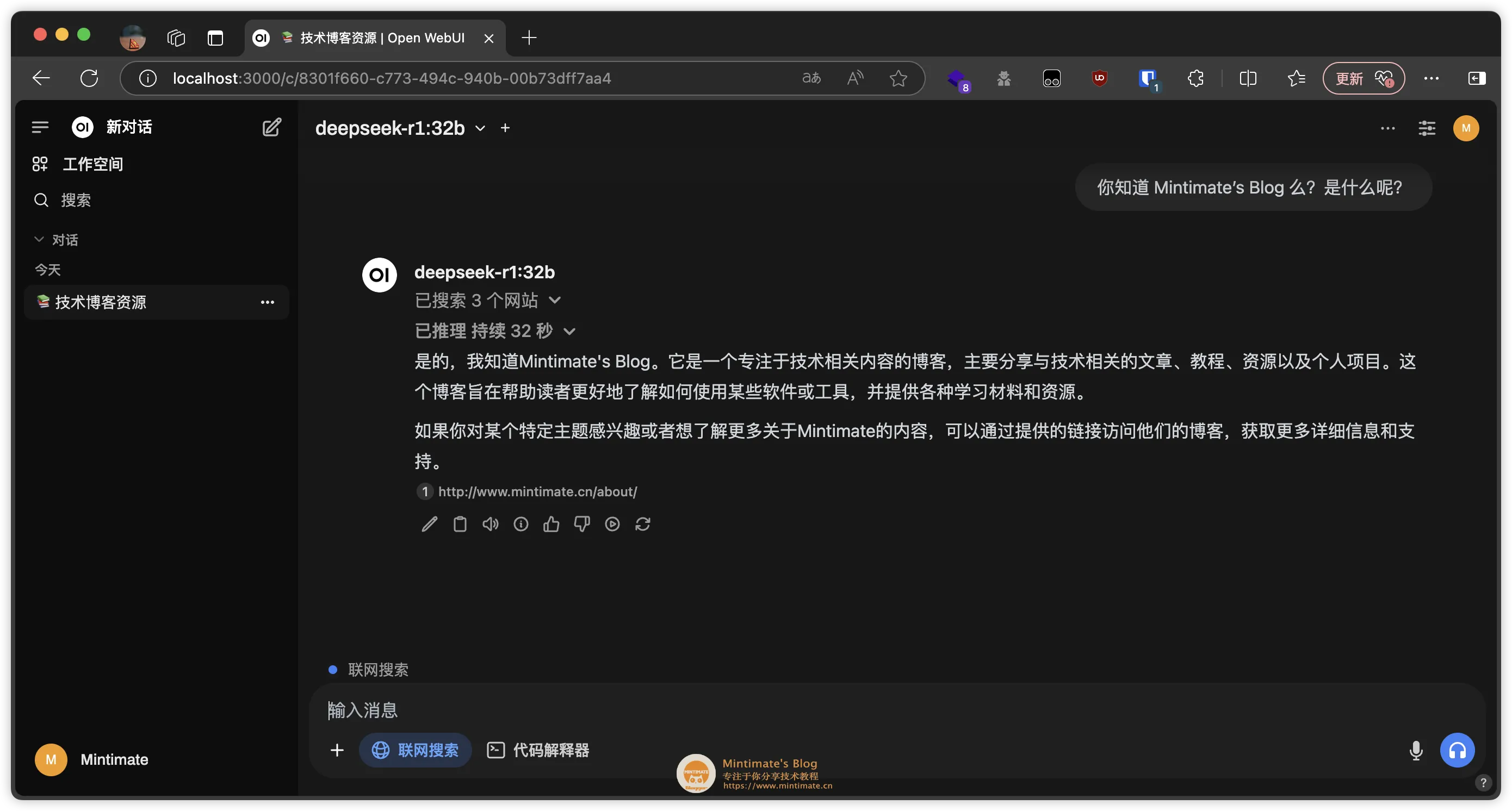
部署思路
目前本地部署 DeepSeek-R1 的途径很多,主流的方法是使用 Ollama + Open WebUI 或者 Ollama + ChatbotUI;我个人是觉得 Ollama + Open WebUI 更加实用,所以我们就部署这两个“小家伙”吧:
- Ollama: 一个轻量级、可扩展的框架,用于在本地计算机上构建和运行语言模型。支持从服务器拉取 Llama 3.3, DeepSeek-R1, Phi-4 和 Gemma 2 等模型。
- Open WebUI: 一个轻量的开源网页 AI 接口 程序,用于在浏览器中调用本地、远程接口语言模型。支持使用 Ollama 模型进行对话、文本生成和文本摘要等任务。
所以,我们是先本地部署 Ollama,之后使用 Ollama 拉取 DeepSeek-R1 模型,最后使用 Open WebUI 调用 Ollama 模型,实现本地运行 DeepSeek-R1 大模型。部署流程如下图所示:
flowchart LR
A[部署 Ollama] --> B[下载 DeepSeek-R1 模型]
C[部署 Open WebUI] --> D[配置 Open WebUI 连接 Ollama]
B --> D
D --> E[开始使用 DeepSeek-R1]
style A fill:#e1f5fe
style B fill:#e3f2fd
style C fill:#e8eaf6
style D fill:#f3e5f5
style E fill:#f1f8e9
我的电脑配置:
- MacBook Pro (14-inch, 2023) M2Max 32GB
开发者爱好群
制作教程不易,寻找教程也不易,找到志同道合的小伙伴更是知音难觅。
- 开发者爱好群: 👉 如果你对云服务器、CDN、云数据库和Linux等云计算感兴趣,亦或者喜欢编程、设计、产品、运营等领域,欢迎加入我们的开发者爱好群,一起交流学习(目前可能就我一个人?🤔,毕竟才刚刚创建~)。
当然,也欢迎在B站或YouTube上关注我们:
- Bilibili: https://space.bilibili.com/355567627
- YouTube: https://www.youtube.com/@mintimate/featured
更多:
Ollama 部署
这里有两个方法可以部署 Ollama,分别是二进制包安装和Docker安装。

安装 Ollama
如果你想要更好的性能,那么推荐使用二进制包安装,因为二进制包安装的 Ollama 性能更好。进入 Ollama Releases 页面,下载最新版本的 Ollama:
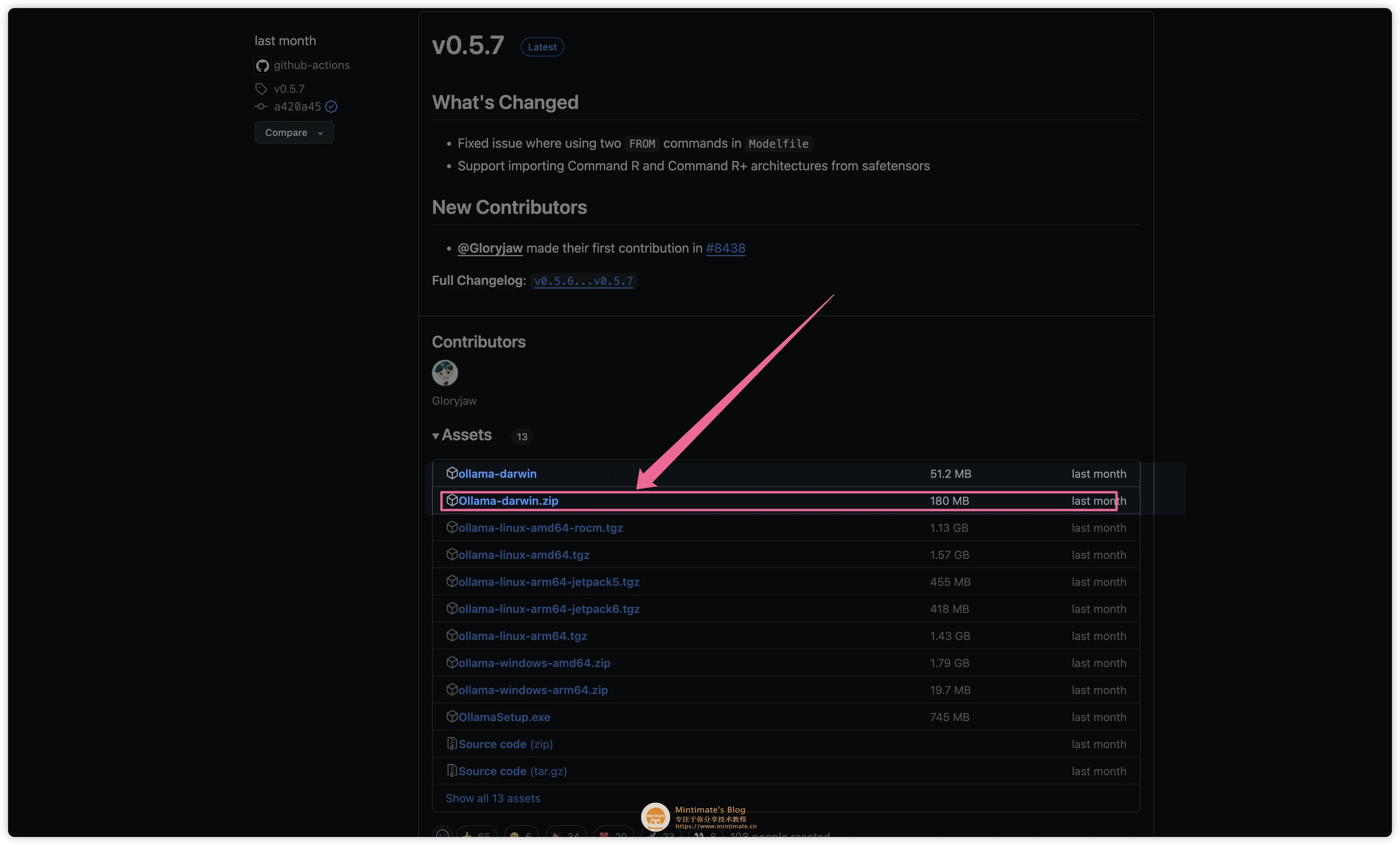
你也可以通过 Ollama 官网的链接,自动下载最新版本的 Ollama:https://ollama.com/download/Ollama-darwin.zip
解压下载的 Ollama 文件,将内部的 Ollama 文件移动到应用文件夹内:
双击打开,点击安装后,即可在终端内调用:
1 | |
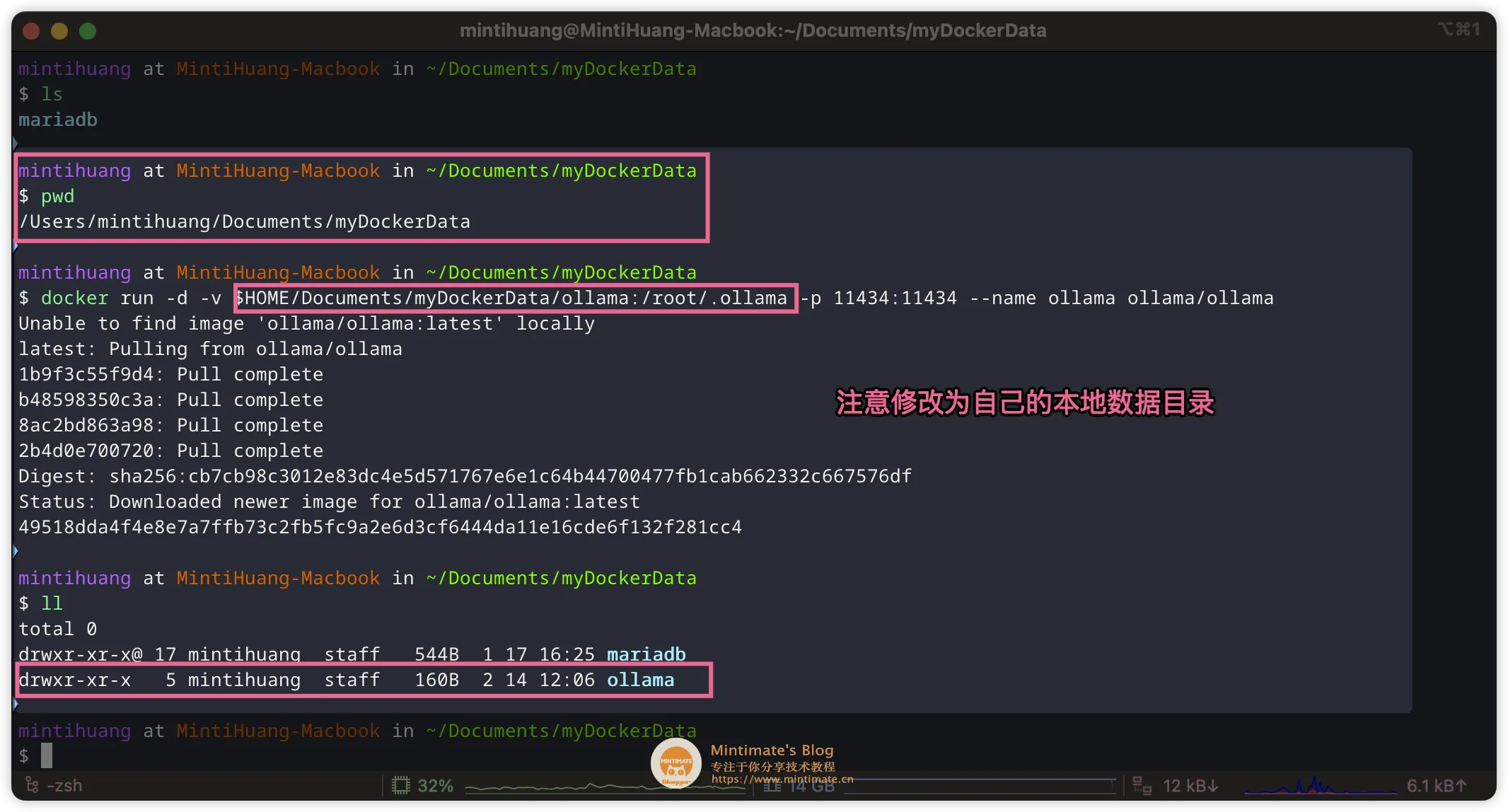
如果你想使用 Docker 部署 Ollama,那么可以参考 Ollama 官方 Docker 镜像。直接拉取 Ollama 的 Docker 镜像:
1 | |
拉取模型
我们可以在 Ollama 的官网查询到模型的 ID: https://ollama.com/library/deepseek-r1
比如我们这次演示使用 32B 蒸馏版本的,那么 ID 就是 deepseek-r1:32b。同时,Ollama 的拉取命令是:
1 | |
复制命令,到终端内执行即可(如果你使用 Docker 版本的 Ollama,那么需要先docker exec -it ollama /bin/bash进入容器内再执行):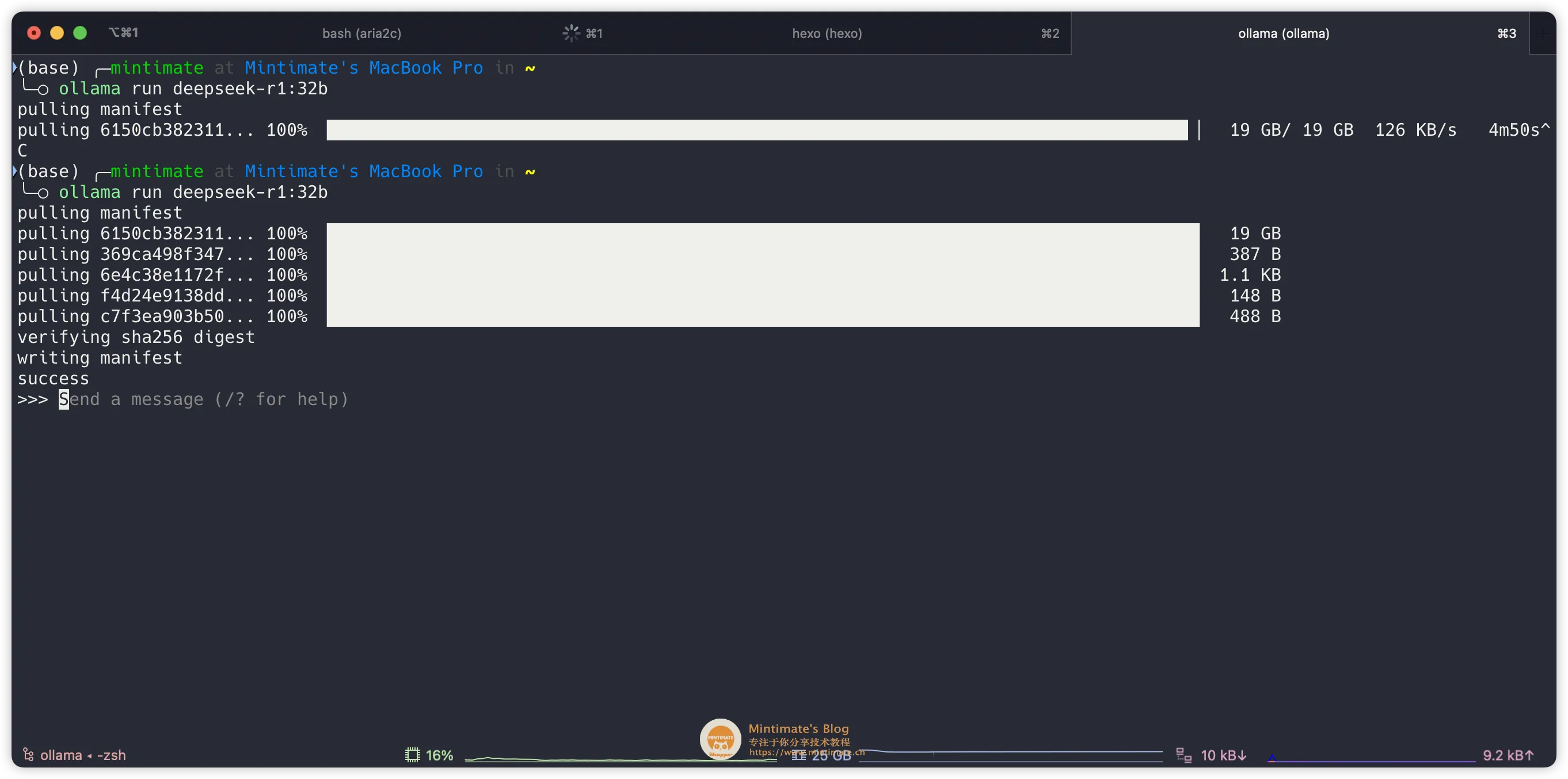
这个时候,相当于我们使用 Ollama 直接运行模型,你可以直接进行提问,比如: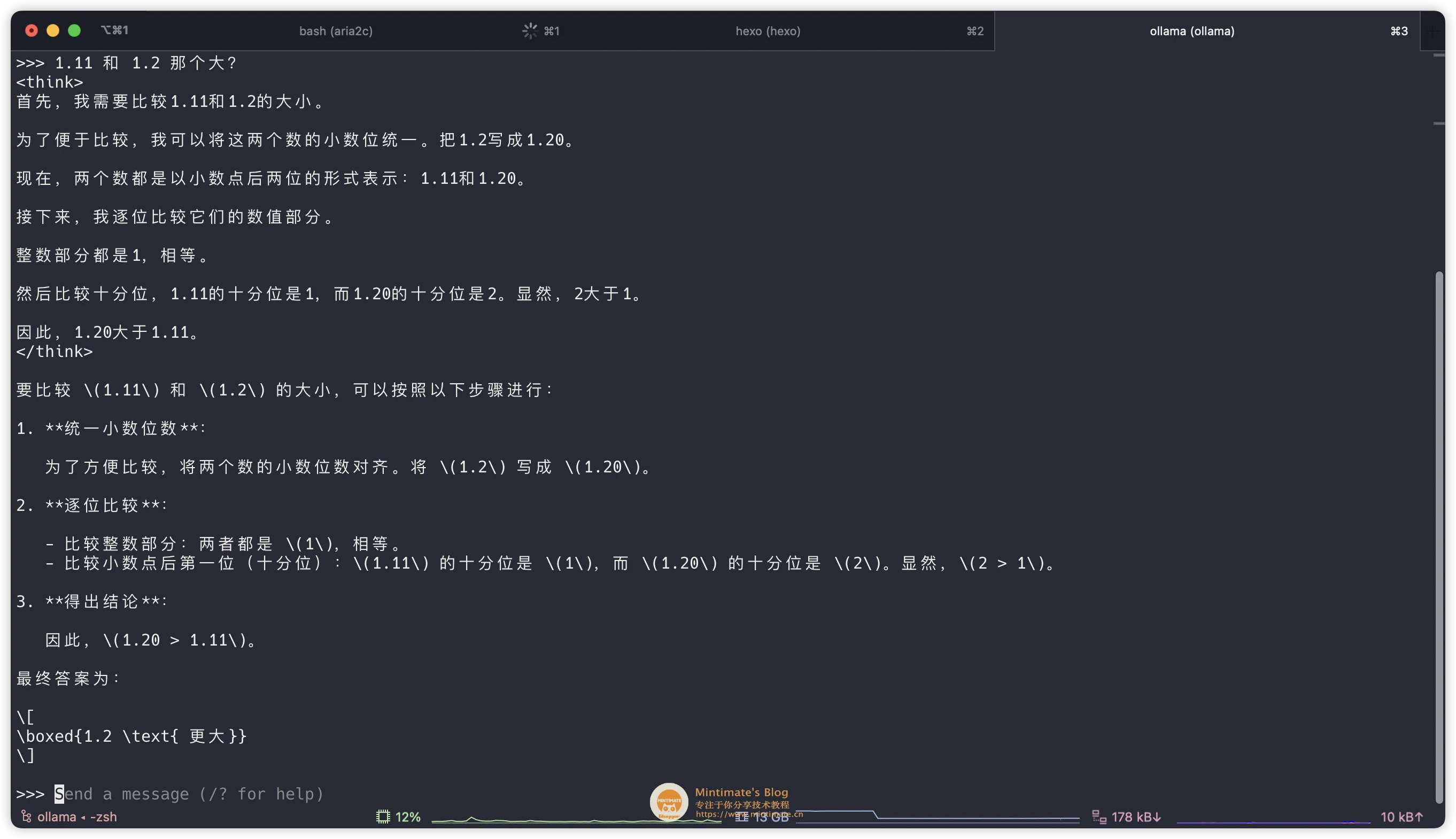
输入/bye,可以退出当前模型交互。后续我们使用 Open WebUI 通过 Ollama 的 API 进行调用。
模型的本地存放地址,在~/.ollama/models内:
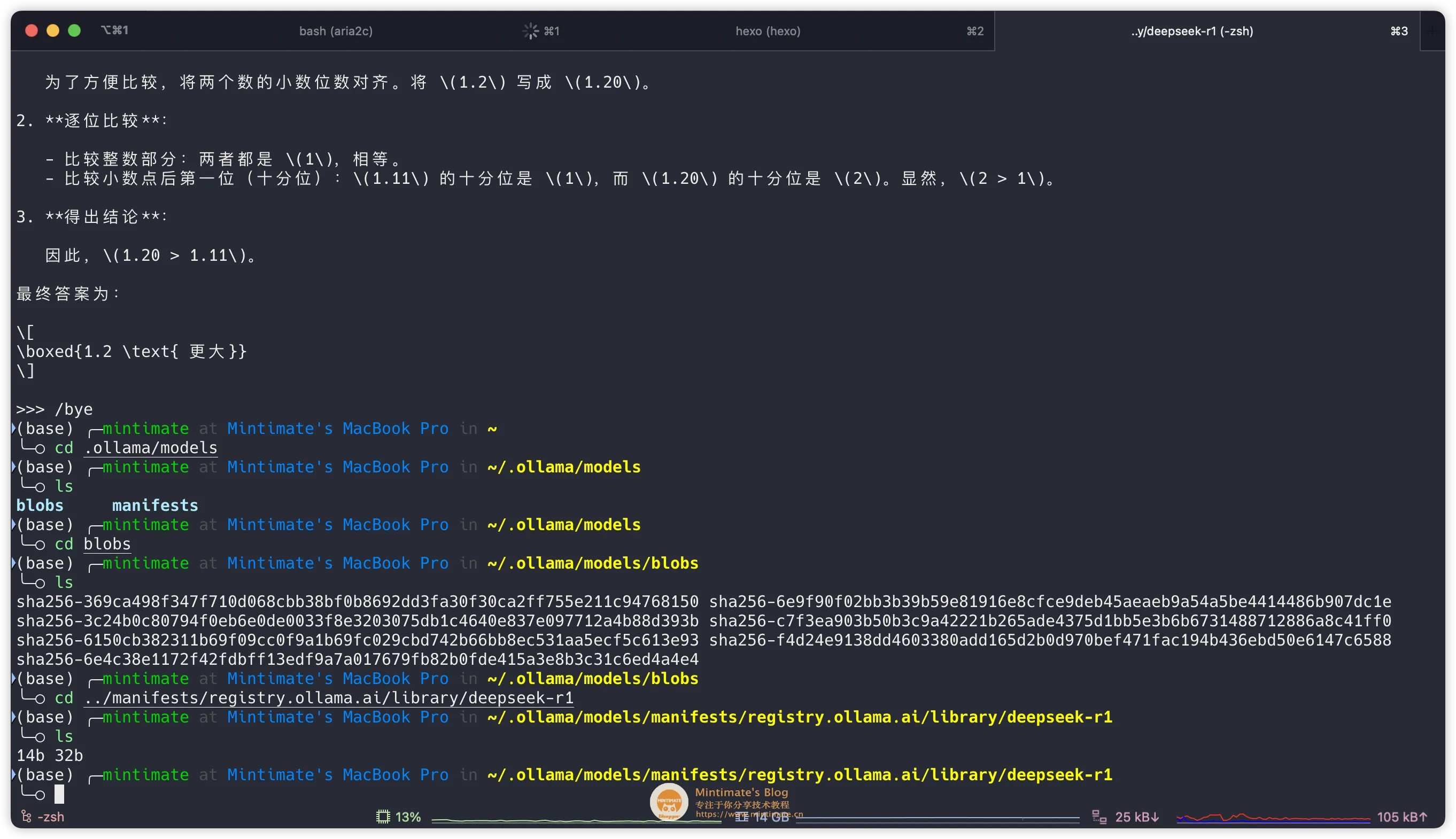
到此,Ollama 和模型就部署完成了。

Open WebUI 部署
同样,有两种方法可以部署 Open WebUI,分别是 Docker 安装和 Python pip 安装。
既没有 Docker,也不想使用 Python? 那么推荐可以试试看 Anything LLM Desktop
如果选择 pip 安装;只需要在 Python 版本≥ 3.8 的情况下,一步即达安装:
1 | |
如果你想使用 Docker 部署 Open WebUI,那么可以参考 Open WebUI 官方文档。直接拉取 Open WebUI 的 Docker 镜像:
1 | |
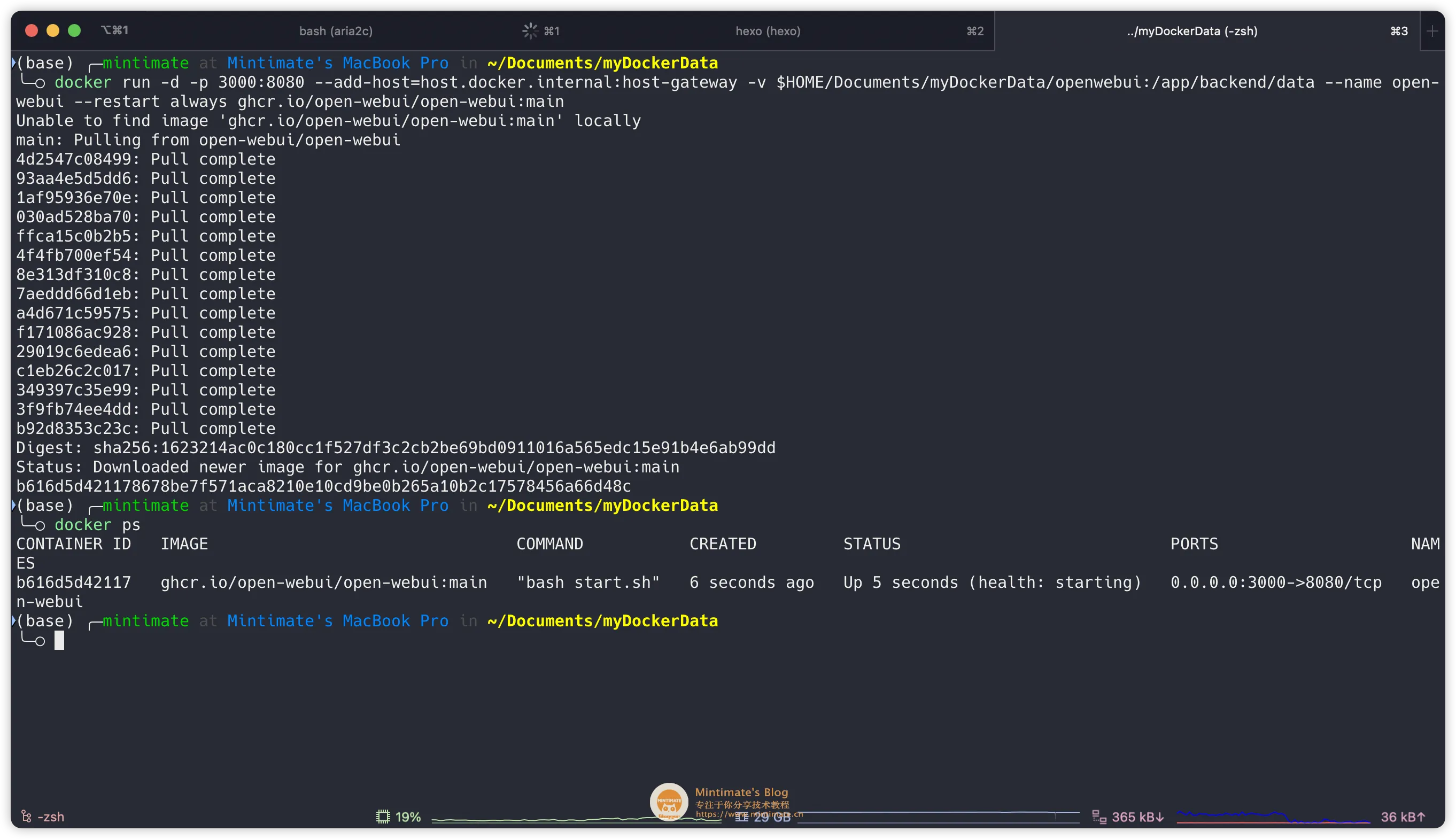
解释一下参数:
-p 3000:8080:将容器的 8080 端口映射到主机的 3000 端口;--add-host=host.docker.internal:host-gateway:将容器内的host.docker.internal解析为宿主机的 IP 地址(通过 host-gateway 动态获取)。
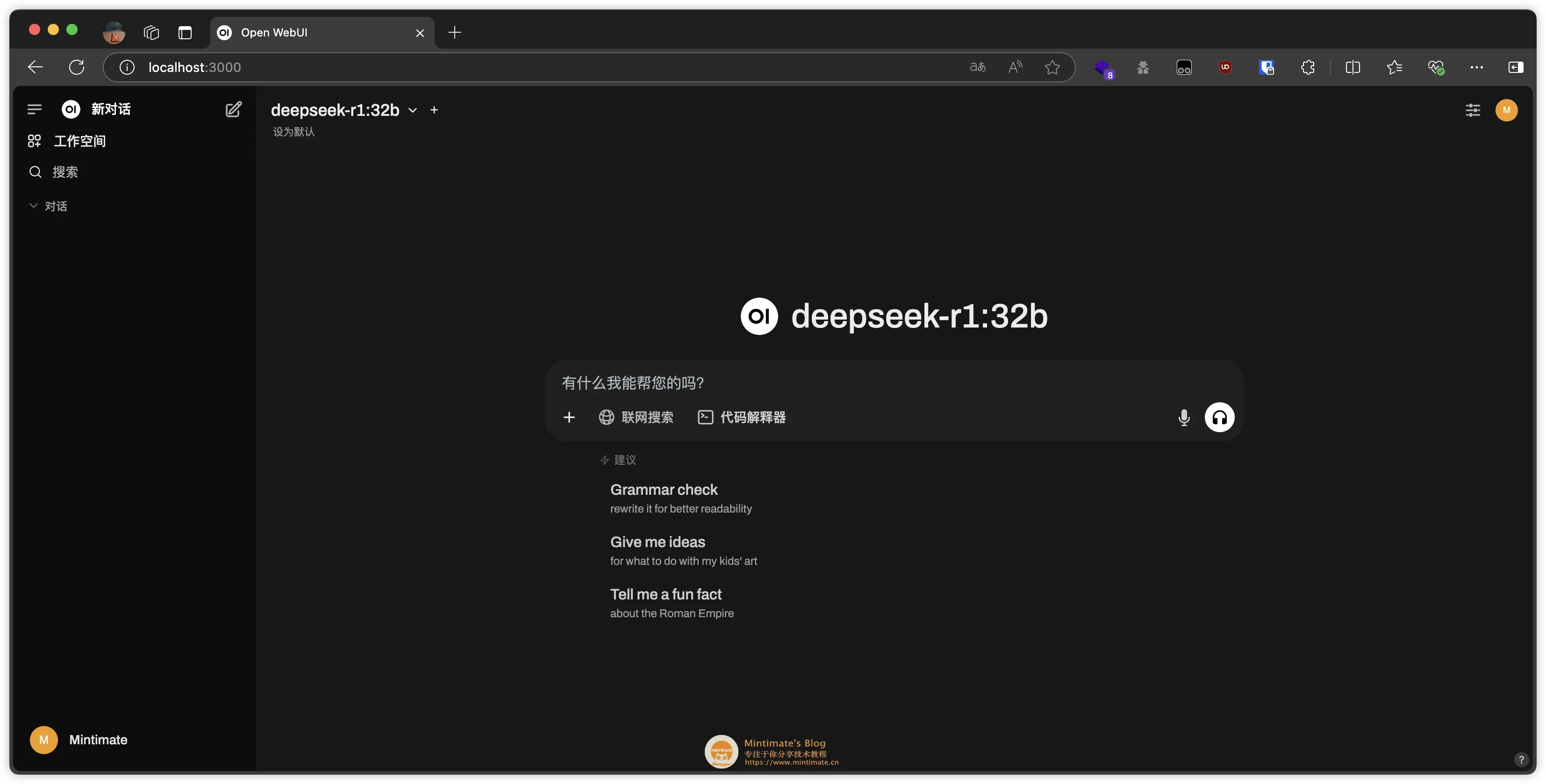
浏览器访问 http://localhost:3000,即可进入 Open WebUI 的界面。根据提示初始化账号即可:
如果开启后,卡在加载界面。可以进入 Open WebUI 的容器内。在
/etc/hosts文件中,添加127.0.0.1 api.openai.com后重启容器。
配置 Open WebUI
其实本地 Open WebUI 和 Ollama 的配置,已经做到了开箱即用。存在部分情况需要设置 API 接口,或者设置远程 ollama 的接口用于本地调用。
API 接口设置
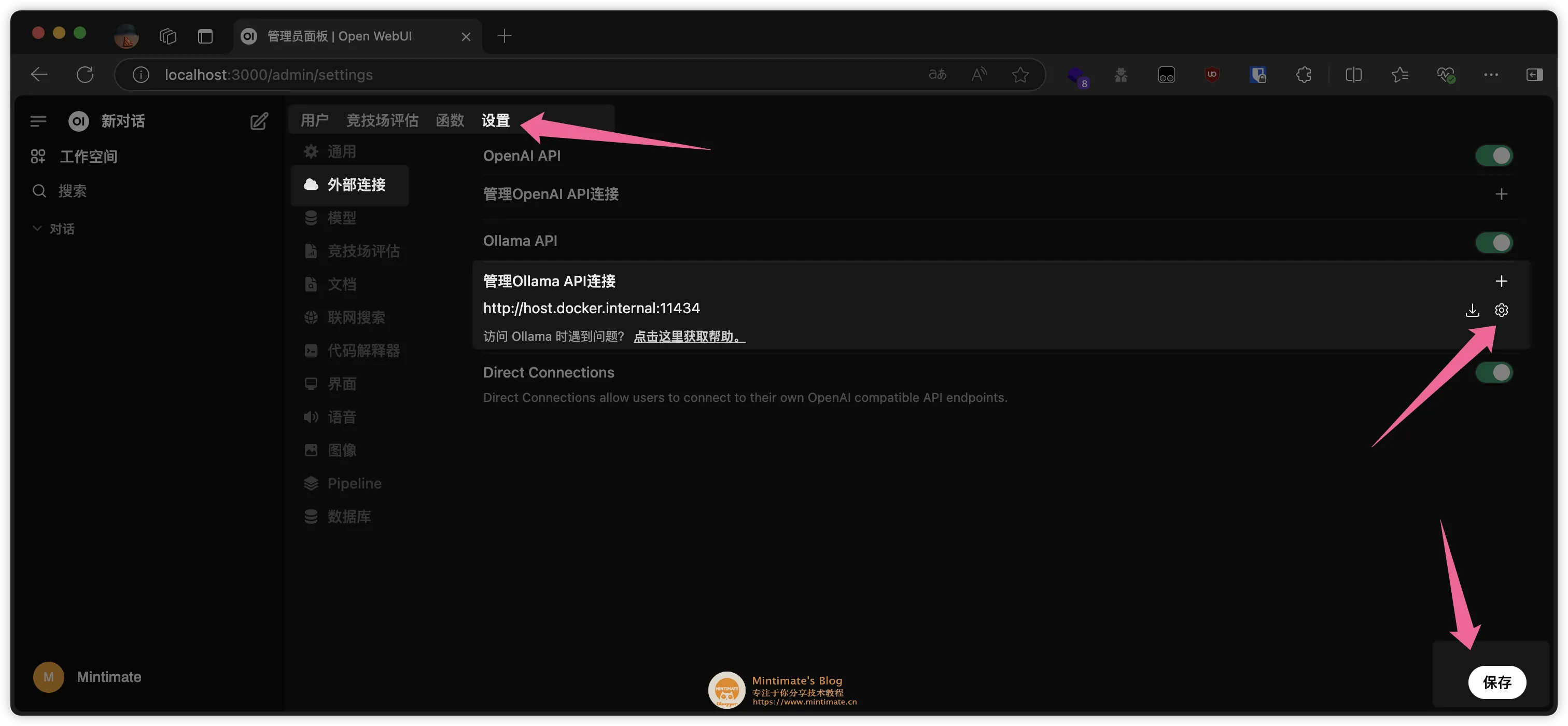
默认情况,Open WebUI 会使用 Ollama 的默认地址 http://localhost:11434 进行查询。没有显示模型,你可以在 Settings 中进行配置:
配置联网查询
联网查询我这里也提一下。一些小白用户,以为联网查询功能,是 DeepSeek 模型提供的;实际上,不管是 DeepSeek 官网,还是 Open WebUI,都是搜索 API 查询了网上结果后,作为 Token 内容喂给模型,之后输出结果。
相当于我们自己网上搜索了一下,把搜索结果作为附件,和提问内容一起给模型,模型输出结果。流程图:
graph LR
A[用户提问] --> B[搜索引擎 API]
B --> C[获取搜索结果]
C --> D[搜索结果作为 Token]
A --> E{LLM 模型}
D --> E
E --> F[生成回答]
style A fill:#f9f,stroke:#333,stroke-width:2px
style B fill:#bbf,stroke:#333,stroke-width:2px
style C fill:#ddf,stroke:#333,stroke-width:2px
style D fill:#fdd,stroke:#333,stroke-width:2px
style E fill:#dfd,stroke:#333,stroke-width:2px
style F fill:#ff9,stroke:#333,stroke-width:2px
Open WebUI 的联网查询,就是使用搜索引擎 API,获取搜索结果。比如,我设置 duckduckgo 作为搜索引擎:
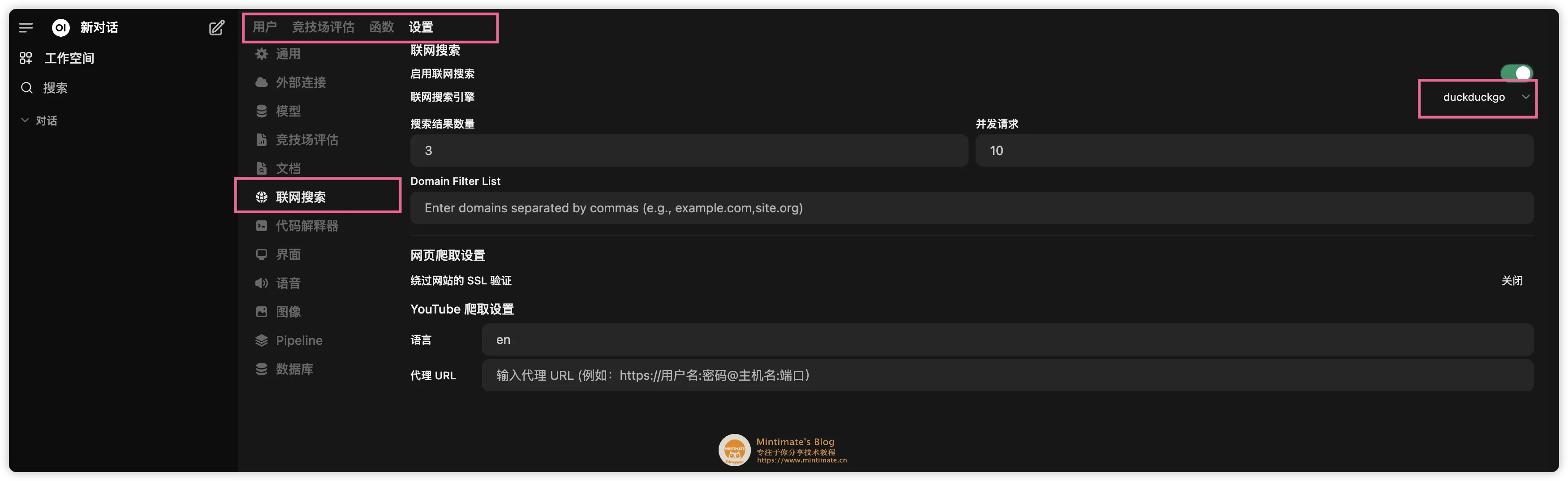
之后,在提问中,即可使用联网搜索功能:
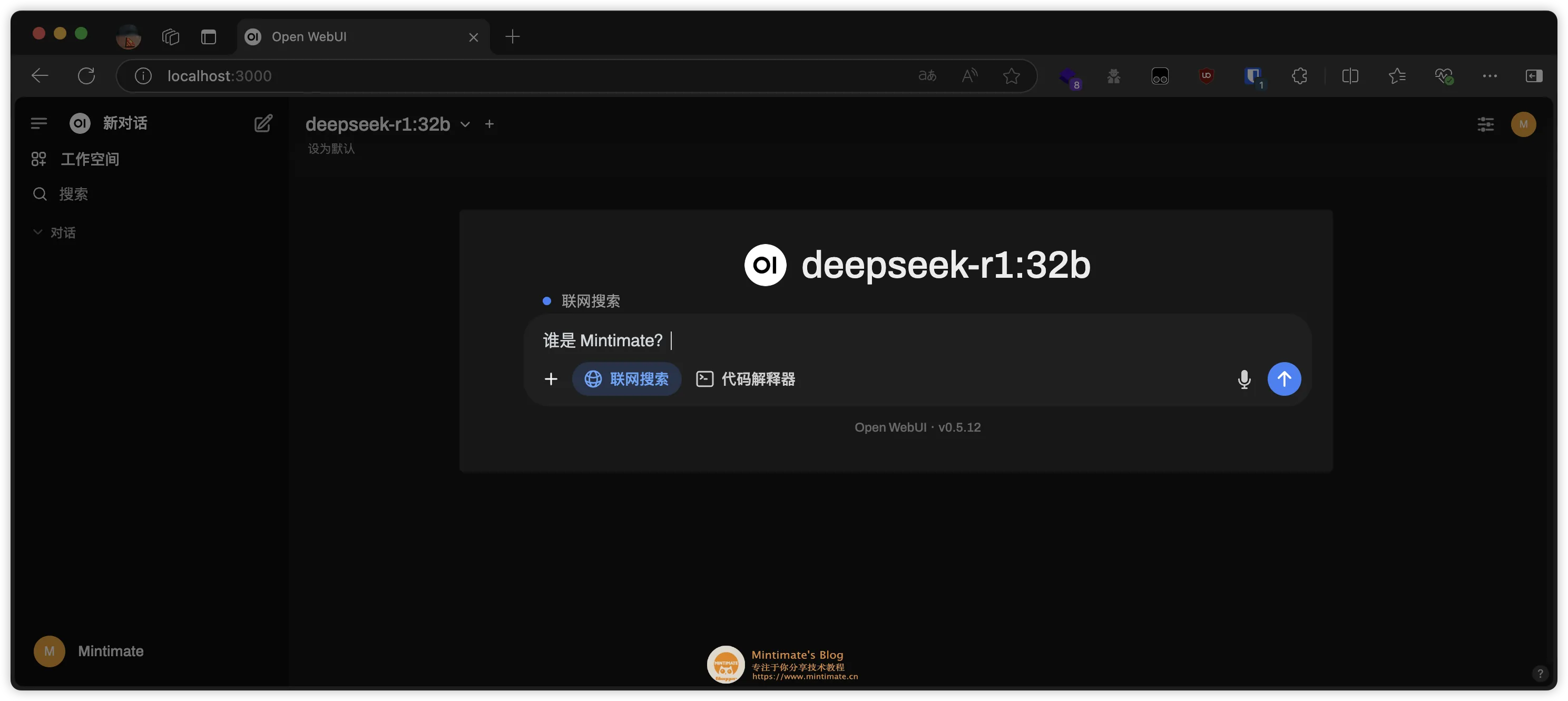
最后的效果:
Q&A
这里,我收集了一些常见的问题,以及解决方案。

如何卸载 Ollama
参考 GitHub issue: How to remove ollama from macos?
注意:移除 Ollama 的配置文件和安装包,只是移除 Ollama 的本地数据,不会影响 Ollama 的模型。
如果你是 docker 部署的,那么移除容器就可以了:
1 | |
如果你是直接安装的,那么需要先移除 Ollama 的配置文件,再移除 Ollama 的安装包:
1 | |
最后,移除 Ollama 的登录项即可。
END
感谢阅读,如果觉得不错,欢迎点赞、评论、转发。如果有什么问题,欢迎在评论区留言。有机会,我们一起看看本地知识库如何构建 ~~
最后,如果你觉得本篇教程对你有帮助,欢迎加入我们的开发者交流群: 812198734 ,一起交流学习,共同进步。
